СЕКРЕТЫ OPENEDGE: УПРАВЛЕНИЕ БАЗАМИ ДАННЫХ OPENEDGE ПРИ ПОМОЩИ OPENEDGE MANAGEMENT
ОПРЕДЕЛЕНИЕ РАЗМЕРА ОБЛАСТИ ХРАНЕНИЯ
Следует определить количество дискового пространства, которое необходимо будет отдать под размещение области хранения. OpenEdge размещает данные и индексы с хорошим уровнем уплотнения. В самом лучшем случае большинство областей, содержащих данные, используются с эффективностью 90 — 95%, а эффективность использования индексных областей лежит всегда около 95%. Для планирования желательно использовать показатель 85%. Это разумное решение. Используя пример из предыдущей главы мы рассчитаем действительный объем данных — 61 миллион байт.

Это – фактический объем данных. Теперь разделим его на ожидаемый процент заполнения. Чем ниже этот процент, тем больше будет занимаемый объем.
![]()
Теперь определим размер в килобайтах — поделим полученное значение на 1024. Этот шаг — необходим, так как при описании структуры БД в st-файле размер областей указывается всегда в килобайтах (независимо от размерности блока БД).
![]()
Итак, в st-файл мы поместим число 70083.
Если в области есть еще несколько объектов, то те же самые вычисления следует сделать для каждого объекта и определить общий размер для области хранения.
ИСПОЛЬЗОВАНИЕ ТОМОВ (ЭКСТЕНТОВ)
Большинство администраторов предпочитает использовать для задания размера тома «двоичные» номера — числа таких размерностей проще всего контролировать из операционной системы. Например, будет сразу видно, что экстент начал расти. Для нашей таблицы-примера можно отвести один экстент постоянного размера в 102400KB (сюда заложено и место для роста таблицы) и один экстент переменной длины (variable extent). Такой том переменной длины должен быть у каждой области — это позволит области расти, если свободное место в фиксированном экстенте закончится. Экстент такого типа лучше не использовать (из-за производительности), но быть он должен всегда. Если такого тома не будет, то области некуда будет расширяться. (кстати, у меня была один раз такая ситуация с 10.1C и неправильным лимитом filesize в операционной системе для пользователя, под которым запускалась БД. База не остановилась, и писала в лог о том, что не может расширить экстент – /dmi).
Экстенты позволяют распределять данные по разным физическим томам (если вы не используете stripe). Например, мы можем разделить 70Mb данных на несколько физических томов. Разделим область на 8 фиксированных экстентов по 10Mb плюс один переменный и распределим чередуя на три разных дисковых устройства.
Как показано на рисунке первый, четвертый и седьмой тома находятся на первом диске, на втором диске — тома номер пять, два и восемь и на третьем — третий, шестой и переменный том с номером девять. OpenEdge заполняет тома по порядку (сначала 10 Mb первого тома, затем 10 Mb второго итд). При использовании такого чередования на каждом дисковом устройстве будет смесь из «старых» и «новых» данных. Такой способ не так хорош, как аппаратное чередование со страйпом размера 128K, но все равно он позволяет более-менее размазать нагрузку на дисковые устройства.
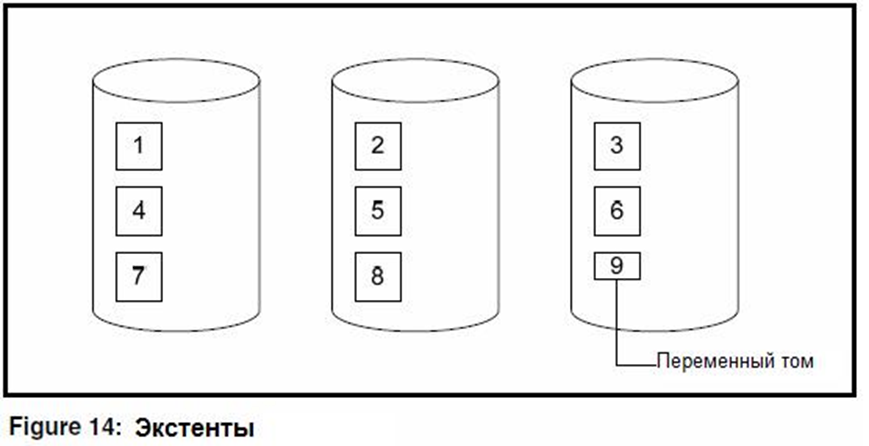
Даже при использовании аппаратного чередования может возникнуть необходимость деления области на экстенты. Только лишь в версии 9.1C Progress сделал возможным поддержку больших файлов для базы данных (да и то — в этой версии не для всех операционных систем — /dmi). Это позволило использовать экстенты размером до 16Gb. Для включения данной возможности необходимо было исполнить утилиту proutil для базы данных с определенным параметром , который включал поддержку больших файлов (см. документацию OpenEdge Data Management: Database Administration). Обычный же лимит — 2GB (и по умолчанию БД не использует файлы больше, чем 2Gb). Если необходимо место для данных, большее, чем 2Gb — необходимо делить область на тома (или включать поддержку).
И еще одна причина — косвенная адресация (indirection). Косвенная адресация начинается тогда, когда одна inode-таблица не может адресовать все физические адреса в файле. Таблица inode хранит данные о содержимом диска и используется для трансляции логических адресов в физические. Если возникает необходимость во второй таблице — то на каждое обращение к БД у нас происходит дополнительное чтение с диска. Это не самым лучшим образом сказывается на производительности системы. Большинство ОС заявляют, что при определенных вариантах могут напрямую адресовать файлы в 4GB. Было проведено тестирование большинства операционных систем и выяснилось, что 1GB — самый безопасный вариант на большинстве современных файловых систем. На серверных версиях Windows следует использовать файловую систему NTFS.
РАЗМЕЩЕНИЕ ИНДЕКСОВ.
До сих пор мы обсуждали только хранение записей. Его очень просто рассчитать, в то время как хранение индексов — нет. Индексное сжатие делает такие расчеты непростыми, а алгоритм сжатия меняется с каждой версией, что еще больше усложняет задачу. Для того, чтобы все упростить — можно проанализировать вывод утилиты dbanalys и использовать ее информацию. Совершенно похожим образом (как и у данных) следует предусмотреть пространство для накладных расходов и роста.
Если база уже есть — статистика и dbanalys даст ответы на все вопросы. Если базы нет — остаётся делать одни прогнозы. Количество и природа индексных областей различно у каждого приложения. Word-индексы и индексы символьных полей используют больше пространства, чем индексы числовых полей. Кроме того, индексы числовых полей более эффективно хранятся. Существуют базы, где индексы занимают больше места, чем данные, но такие базы — исключение.
В общих чертах — индексы занимают, как правило, 30% от всего размера хранимых данных. Поэтому, для определения размера индексных областей достаточно заложить 50% от размера данных. Помните, что этот процент может различаться в зависимости от схемы данных. Таким образом, эту оценку следует рассматривать только лишь как начальную точку в расчетах.
Пример ниже рассматривает часть вывода утилиты dbanalys, которая показывает пропорциональное отношение между данными и индексами в существующей БД. Эту информацию можно использовать для определения выделяемого пространства под области данных и индексов.
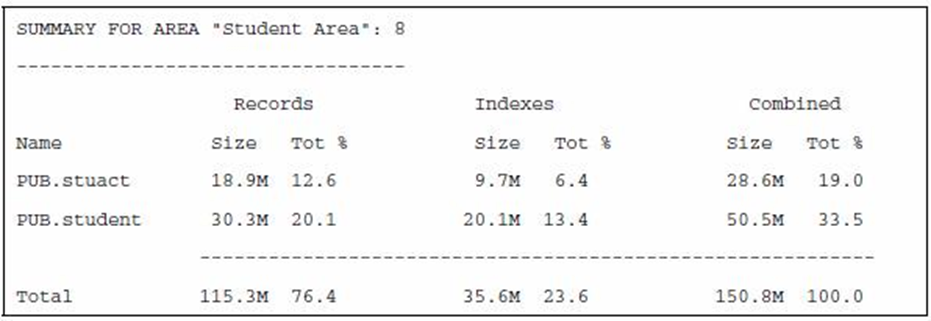
ЖУРНАЛ BEFORE-IMAGE
Нам следует побеспокоиться и о размере области, отведенной под журнал before-image (или — область primary recovery). Эта область постоянно ответственна за поддержку целостности базы данных и является очень важной. Основная нагрузка этой области — нагрузка на запись. Если область расположена на медленных дисках, то операции обновления данных в базе будут такими же медленными. Размер области зависит от активности по обновлению данных и от длины транзакций.
Область primary recovery состоит из кластеров, размер кластеров можно настроить. При обновлении записи БД создаются заметки об этом обновлении, которые и записываются в эту область . Если в транзакции возникла ошибка или пользователь решил отменить (undo) изменения этой транзакции, то эти заметки используются для корректного отката всех произошедших внутри транзакции изменений .
Для примера предположим, что нам надо увеличить на 10 процентов значение одного конкретного поля для всех записей в таблице. Для изменения надо использовать стратегию «всё-или-ничего» , так как мы не сможем определить на каком месте аварийно закончилось обновление. В этом случае нам необходима одна большая транзакция, внутри которой мы будем производить изменения. Если произойдет ошибка, то все измененные поля в записях «откатятся» к своим первоначальным значениям. Важно знать, что если у нас выполняется одновременно несколько больших процессов, то размер области before-image может стать довольно значительным.
Давайте рассмотрим структуру и использование данной области подробнее. Эта структура представляет собой связанный список кластеров, размер которых может быть изменен в широких пределах — от 8Kb до более чем 256Mb.

Чем меньше размер кластера, тем чаще наступает событие именуемое какcheckpoint. Checkpoint – это точка синхронизации буферной памяти БД и дисковой системы. Может возникнуть желание сделать наступление checkpoint как можно редким из-за соображений производительности, но тем самым мы увеличиваем время на процессы восстановления (recovery) базы данных.
Как же определить правильный размер кластера before-image ?
- Необходимо наблюдение за БД во время наибольшей активности на обновление
- Сбор статистики при помощи OpenEdge Management
- Наблюдение за интервалами между checkpoint’ами в течении недели
В идеальном случае, событие checkpoint должно наступать не чаще, чем один раз в две минуты. Если это событие наступает чаще, то необходимо увеличить размер кластера before-image. Это не означает, что при более редких checkpoint’ах нам необходимо уменьшать размер кластера bi-файла. Значение по умолчанию — 512Kb. Это достаточно для маленьких систем с редкой транзакционной активностью. Для большинства других систем больше подходят значения из диапазона 1024 — 4096Kb.
ПРОСМОТР ИНФОРМАЦИИ О СОБЫТИЯХ CHECKPOINT В OE MANAGEMENT
Из верхнего меню выбрать «Resources» и необходимую нам базу данных
Выбрать опцию «Page Writers» из секции «Operations Views» страницы ресурсов БД.
На иллюстрации ниже — пример раздела «Checkpoint summary»
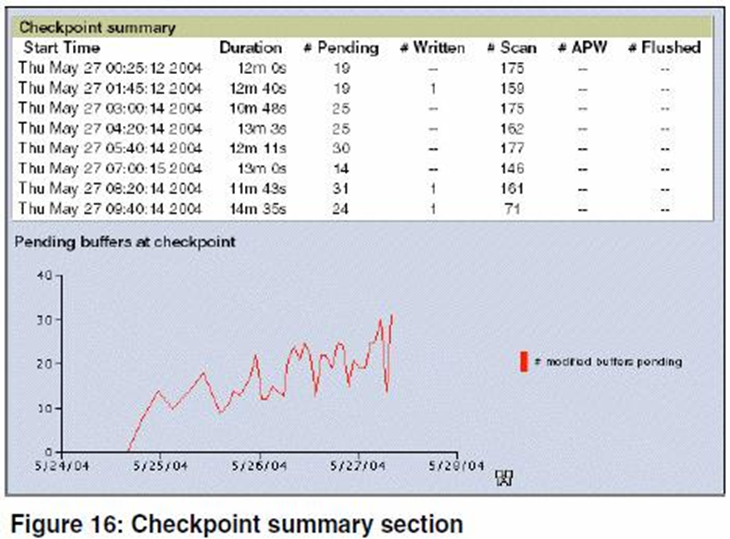
Как уже и говорилось, размер кластера влияет на частоту наступления событийcheckpoint. Пользователи изменяют данные в буферной памяти БД, лежащую в разделяемой памяти (shared memory) и заполняют кластер bi-файла заметками об этом. Процессы APW (Async Page Writers, асинхронные страничные писатели) постоянно сканируют память в поисках модифицированных буферов для сброса их на диск. Во время первого checkpoint все модифицированные буфера помещаются в очередь. Буфера из этой очереди должны быть сброшены на диск процессами APWдо наступления следующего checkpoint. Приоритет записи из такой очереди больше, чем для записи на диск текущих модифицированных буферов. Если вся очередь сброшена на диск успешно, то появляется время на обработку этих буферов. Наша цель — чтобы так и происходило. Если же буферы из этой очереди за оставшееся время сбросить на диск не удается, то обработка текущих модифицированных буферов приостанавливается до полного исчерпания оставшейся очереди. Если интервал событий checkpoint лежит в разумных временных рамках и все же при наступлении checkpoint происходит сброс буферов (flushing buffers at checkpoint), то необходимо добавить один или несколько APW-процессов и посмотреть, что из этого получится. Обычно добавление APW помогает, если нет — добавьте еще один процесс и оцените результат. Если добавление APW-процессов перестало улучшать картину, то необходимо искать узкое место в дисковой подсистеме.
Мы обсудили структуру области primary recovery, но не её размер. Универсального рецепта нет — все зависит от приложения. Но одно сказать можно — из-за соображений производительности необходимо изолировать раздел, содержащий эту область, от других томов БД. Если база у нас одна, то можно вынести эту область на отдельный раздел-зеркало (RAID1). При наличии нескольких БД области primary recovery можно разместить на защищенных массивах с чередованием (RAID10) для увеличения пропускной способности.
Метка:OpenEdge, OpenEdge Management
Вам также может понравиться
