
Производительность серверов БД в OE 12
Тесты производительности, сравнивающие недавно выпущенный многопоточный сервер баз данных (Multi-Threaded Progress® OpenEdge® Database Server for ABL) с классическим однопоточным сервером, показывают, что в некоторых тестах одни и те же операции выполняются в три раза быстрее. Эта статья объясняет философию, лежащую в основе выполненных тестов, и даёт представление об исполняемых сценариях и полученных статистических данных.
Повышению производительности в OpenEdge 12.x способствует улучшение трёх основных функций:
- Buffer Pool Hash Table (BHT)
- Multi-threading of the OpenEdge Database Server for ABL (MTDBS)
- Server-Side Join (SSJ)
Задача MTDBS в том, чтобы преимущества развёртывания OpenEdge в многоуровневой архитектуре перевешивали любое влияние на производительность сетевых подключений по TCP (client-server) по сравнению с прямыми подключениями к разделяемой памяти (self-service).
Как правило не ожидается, что работа в клиент-серверной сетевой среде (CS) будет лучше, чем при прямом самообслуживающимся подключении (SS). Хотя существуют примеры, когда использование новой технологии SSJ показывает такое улучшение производительности. Скорее ожидается, что работающие в многопоточном режиме сервера баз данных OpenEdge превзойдут свой однопоточный аналог. Проблемы, которые эти функции преодолевают, должны стать предметом разногласий в существующем развёртывании в процессе реализации улучшений производительности. С точки зрения улучшений в BHT будет уменьшена конкуренция за текущий латч хэш-таблицы буферного пула. С точки зрения MTDBS узким местом может быть выполнение запроса-ответа сервером базы данных. А для SSJ запросы должны использовать новую технологию.
Далее рассмотрим подробнее что было сделано для реализации этих функций.
Улучшение производительности BHT
Хэш-таблица буферного пула (BHT) – это хэш-таблица, которая содержит указатели на блоки базы данных, которые были скопированы в буферы, хранящиеся в буферном пуле базы данных (-B). Каждый просмотр буферного пула, включая для доступа к индексам и данным, использует BHT для определения местоположения этих данных в разделяемой памяти. BHT обеспечивает быстрый поиск данных в буферном пуле всякий раз, когда пользовательское приложение запрашивает данные.
Как и большинство механизмов хеширования, BHT принимает в качестве входных данных хэш-ключ (уникальный ключ блока базы данных) и применяет к нему функцию хеширования, чтобы найти запись в таблице BHT. Как и большинство хэш-таблиц, которые не связывают хэш-ключ с данным один к одному, каждая запись BHT фактически является «корзиной» элементов, организованных в виде связанного списка указателей буферного пула (см. Рис.1). Таким образом, уникальный ключ блока базы данных или ROWID сопоставляется с соответствующим буфером в буферном пуле (-B).
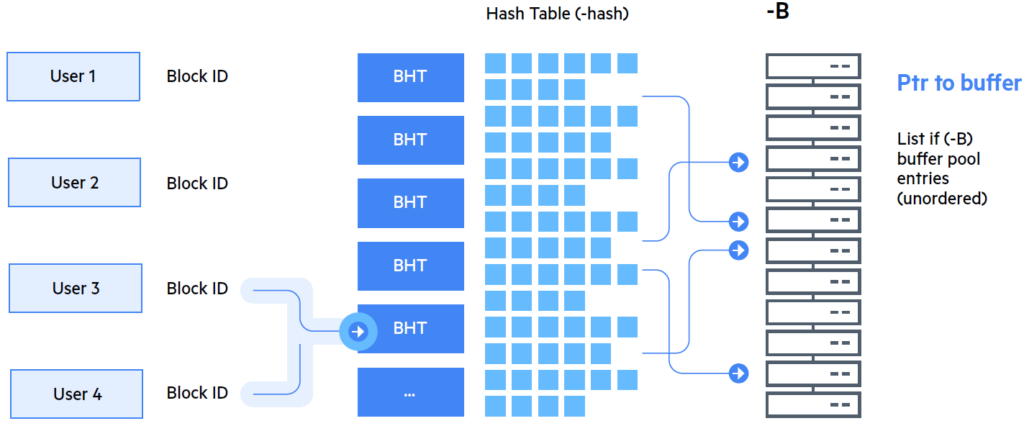
По умолчанию размер BHT приблизительно равен 25% от размера буферного пула (-B), который можно изменить, указав другое значение для параметра старта базы данных -hash. По мере того, как страницы блоков входят и выходят из буферного пула, должны обновляться соответствующие BHT-записи. А так как BHT является модифицируемой структурой, доступ к ней должен быть защищён во время изменения. Доступ защищён серией BHT-латчей, которые обеспечивают эксклюзивный доступ к BHT-секциям. Статистика активности BHT-латча, сообщаемая системой, представляет собой суммирование информации о нескольких используемых латчей BHT.
Для повышения эффективности доступа к BHT применялись два отличающихся метода. В первом, нужно было улучшить параллелизм BHT путём уменьшения объёма информации, заблокированной эксклюзивным доступом для отдельных поисков. Во втором, необходимо полностью избежать ненужного использования BHT за счёт оптимистичного подхода к доступу к индексным данным в буферном пуле базы данных.
Как отмечалось ранее, доступ к данным должен быть защищён поскольку информация, хранящаяся в структуре данных BHT, является общей для всех подключений и изменяется по мере того, как страницы данных входят и выходят из буферного пула. Данные защищены с помощью механизма латчей, который обеспечивает исключительный доступ к структуре данных так, чтобы структура не изменялась для отдельного поиска.
Такая высоко-доступная структура данных может стать предметом разногласий, когда многие соединения баз данных запрашивают данные одновременно. Поэтому чтобы увеличить параллелизм одновременного поиска, BHT должен быть защищён несколькими латчами, а не одним. А поскольку BHT разбит на защищённые отдельными латчами секции, то параллелизм улучшается за счёт уменьшения объёма данных, защищённых исключительным доступом одним BHT-латчем.
Проблема состоит в том, чтобы определить, сколько латчей должно быть предусмотрено для защиты BHT. Это баланс объёма выделяемой памяти по сравнению с производительностью. Установка «один к одному», как правило, работает лучше всего, но использует больше памяти. Кроме того, это усложняет механизм, когда необходимо удерживать более одного латча BHT одновременно.
За несколько выпусков OpenEdge количество латчей, защищающих BHT, увеличилось с 1 до 4, затем до 256 и до 1024. Однако размер буферного пула базы данных (-B), устанавливаемого клиентами, также увеличился. Нередко можно увидеть -B, установленную миллионами. Например, при -B, равном 6 000 000, примерно 6000 указателей буферного пула BHT будут заблокированы исключительно каждым запросом данных. Кроме того, клиенты работают с большим числом подключений к базе данных (-n), что увеличивает конкуренцию за одновременный доступ к общим данным.
Предыдущие попытки улучшить производительность BHT с помощью латчей чтения/записи не показали многообещающих результатов в этой среде, вероятно, из-за накладных расходов на их реализацию. А поскольку процессоры становятся быстрее, это может потребовать дополнительных исследований.
Вместо того чтобы просто увеличить количество латчей до некоторого большего значения, был введён коэффициент хеширования латчей, который устанавливает количество латчей BHT в процентах от BHT (-hash). Поскольку-хэш изменяется по мере увеличения -B, то увеличивается и количество латчей, защищающих адреса записей буфера, указанных в BHT. Поэтому ожидается, что это усовершенствование будет продолжать улучшать параллелизм случайных обращений BHT независимо от растущего размера -B.
В дополнении к улучшению одновременного доступа к случайным данным через BHT, ещё один способ повысить производительность в этой области заключается в том, чтобы полностью избежать ненужного эксклюзивного доступа к общему ресурсу. При обращении к данным доступ к ним осуществляется через ROWID, который обычно получается из индексного поиска. Для поиска отдельных записей одним из направлений улучшения производительности доступа BHT была реализация технологии коэффициент хеширования латчей, о которой было рассказано выше.
Дальнейшее улучшение поиска при сканировании нескольких записей, например в операторе «for each» или «query», может быть достигнуто с помощью техники «базы данных в памяти» (in-memory database), позволяющей сократить количество обращений к BHT для получения необходимых ROWID из соответствующего индекса. Этот метод делает существующий пессимистический алгоритм оптимистичным алгоритмом, предполагая, что расположение в памяти последнего индексного блока, к которому обращались, не изменится до следующего поиска.
Индексы, поддерживаемые в базе данных OpenEdge, используют технику, которая сильно сжимает данные в отдельном индексном блоке. Поэтому индексный блок может содержать тысячи индексных записей, используемых для извлечения идентификаторов строк, которые удовлетворяют конкретному запросу. Оба механизма SQL и ABL запрашивают идентификаторы строк из индекса последовательно, чтобы удовлетворить запрос по одному за раз. Несмотря на то, что индексный курсор всегда запоминает номер блока базы данных, к которому последний раз обращались, при каждом обращении к индексному блоку, он использует BHT, чтобы найти, где находится индексный блок в памяти. Этот алгоритм защищает от ссылки на запомненный индексный блок, который больше не находится в пуле буферов базы данных.
Это пессимистичный подход к доступу к данным. Благодаря тому, как происходит управление буферами базы данных в буферном пуле, крайне редко случается так, что индексный блок, к которому только что обращались, будет выгружен из буферного пула до следующего поиска. Изменение алгоритма на оптимистичный, то есть предполагающий, что последний индексный блок, к которому обращались, всё ещё будет существовать в буферном пуле и точно в том же месте при следующем обращении, означает, что нет необходимости обращаться к BHT для его поиска.
Устранение необходимости в эксклюзивном доступе к любой структуре данных – это лучший способ улучшить параллелизм. Конечно, чтобы гарантировать, что доступ по запомненному адресу обеспечит доступ к желаемому буферу, должна быть выполнено соответствующая проверка, но такая проверка уже выполнена для существующего пессимистичного алгоритма, поэтому для использования оптимистичного подхода не требуется никаких дополнительных затрат.
В редких случаях, когда буфер может оказаться не тем, который требуется, его поиск будет выполнен как в прошлом с использованием BHT. В зависимости от удовлетворяющих определённому запросу количества индексных записей, этот оптимистичный подход может в тысячи раз сократить количество поисков с использованием BHT на каждый сканируемый индексный блок.
Многопоточность сервера баз данных OpenEdge
Несмотря на то, что к данным в базе можно получить многопоточный доступ через Progress Application Server for OpenEdge, OpenEdge SQL и различные утилиты базы данных, а также сами сервера базы данных, которые взаимодействуют с удалёнными ABL-клиентами, не используют потоки.
Целью реализации многопоточности для серверов базы данных, было увеличение объёма данных, которые могут одновременно извлекаться отдельным сервером, который обслуживает несколько удалённых клиентов. В результате полученное преимущества от развёртывания многоуровневой архитектуре OpenEdge покрывает любое влияние на производительность из-за сетевых подключений по TCP.
При использовании однопоточного сервера параллельные запросы от нескольких удалённых клиентов обрабатываются последовательно (см. Рис.2). Поскольку количество параллельных запросов от разных удалённых клиентов к одному и тому же серверу баз данных увеличивается, производительность поиска данных для любого отдельного удалённого клиента будет снижаться, так как запросы удалённых клиентов обрабатываются одним сервером. В больших системах с большим количеством параллельных удалённых запросов это может стать узким местом для извлечения данных из базы данных.
Кроме того, в однопоточной модели единственный серверный поток должен выполнять и другие задачи, которые он должен делать в дополнение к простой обработке данных удовлетворяя запросы удалённого клиента. Некоторые из них ожидают и обрабатывают новые запросы на подключение, обрабатывают запросы на отключение и решают конфликты блокировки записей для своих подключений. Эти дополнительные задачи выполняются за счёт одновременной обработки запросов на извлечение данных для удалённых клиентов одним и тем же сервером.

Когда удалённый клиент сталкивается с конфликтом блокировки записей, его сервер приостанавливает обработку запроса этого удалённого клиента и продолжает обрабатывать запросы других удалённых клиентов. В случае разрешения конфликта блокировки записи, ожидающий удалённый клиент не будет реализовывать свои записи до тех пор, пока все остальные отложенные задачи не будут выполнены сервером. Это не только влияет на производительность ожидающего удалённого клиента, но и когда конфликты блокировки записей не обрабатываются как можно скорее, они могут создать очередь из необработанных блокировок, если другие клиенты ожидают доступа к той же записи. В зависимости от частоты конфликтов, блокировки записей могут негативно влиять на общую производительность всей системы, как CS, так и SS запросов.
Многопоточный подход MTDBS заключается в предоставлении одного потока для каждого удалённого клиента, обслуживаемого сервером, и в предоставлении дополнительных потоков для выполнения дополнительных задач, выполняемых одним и тем же сервером. Каждый отдельный поток может одновременно извлекать данные из базы данных. В этом случае удалённому клиенту больше не нужно ждать завершения запроса другого клиента, и он не будет ожидать пока сервер обработает запросы на подключение или отключение (см. Рис.3).
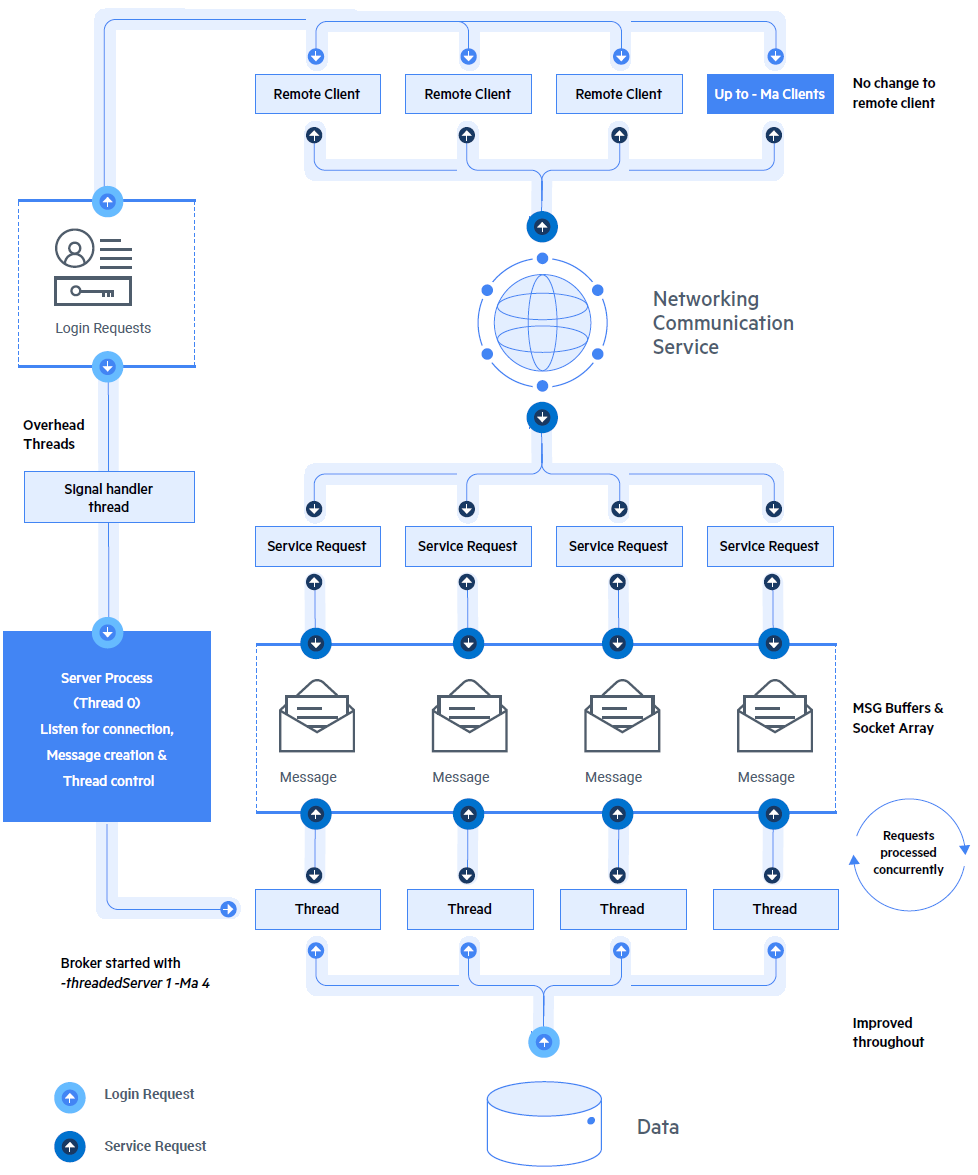
С помощью MTDBS поток, ответственный за обработку запросов удалённых клиентов, будет ожидать разрешения блокировки записи почти так же, как это было бы при соединении SS. Таким образом, конфликты блокировки записей будут обрабатываться сразу же после их разрешения, что может значительно повысить общую пропускную способность системы.
Развёртывание приложения в такой среде не требует изменений в самом приложении. Одно и то же приложение может работать с использованием MTDBS, классической среды с CS или SS подключениями. Это также не влияет на развёртывание приложений с использованием серверов приложений, которые удалённо подключаются к базе данных. Они тоже будут пользоваться преимуществами работы с MTDBS.
Несмотря на то, что может быть настроен только один сервер MTDBS для поддержки всех удалённых подключений отдельного развёртывания, это не является рекомендуемой конфигурацией, так как поскольку, когда один MTDBS столкнётся с проблемой, это может повлиять на всех клиентов развёртывания. Прагматичный подход к распределению рабочей нагрузки удалённых клиента между несколькими серверами MTDBS по-прежнему является лучшим вариантом для обеспечения высокого уровня доступности при сбалансированном использовании ресурсов.
Примечание: если применить сигнал kill -SIGUSR1 к процессу сервера MTDBS, то будет выполнена трассировка стека для всех его потоков.
Server-Side Joins
До внедрения технологии SSJ, когда удалённый клиент формирует запрос с объединением данных из нескольких таблиц, большая часть такого объединения происходило на стороне клиента. Поэтому даже записи, которое некогда не будут использованы, будут отправлены клиенту по TCP. В результате, в зависимости от скорости сети, это может отрицательно повлиять на производительность.
Чтобы избежать этого, было решено внедрить технологию SSJ, которая для определенного набора запросов, требующих объединений, будет выполнять объединения на стороне сервера. Таким образом, клиенту по сети будут отправлены только те записи, которые удовлетворяют условию запросу (см. Рис. 4).
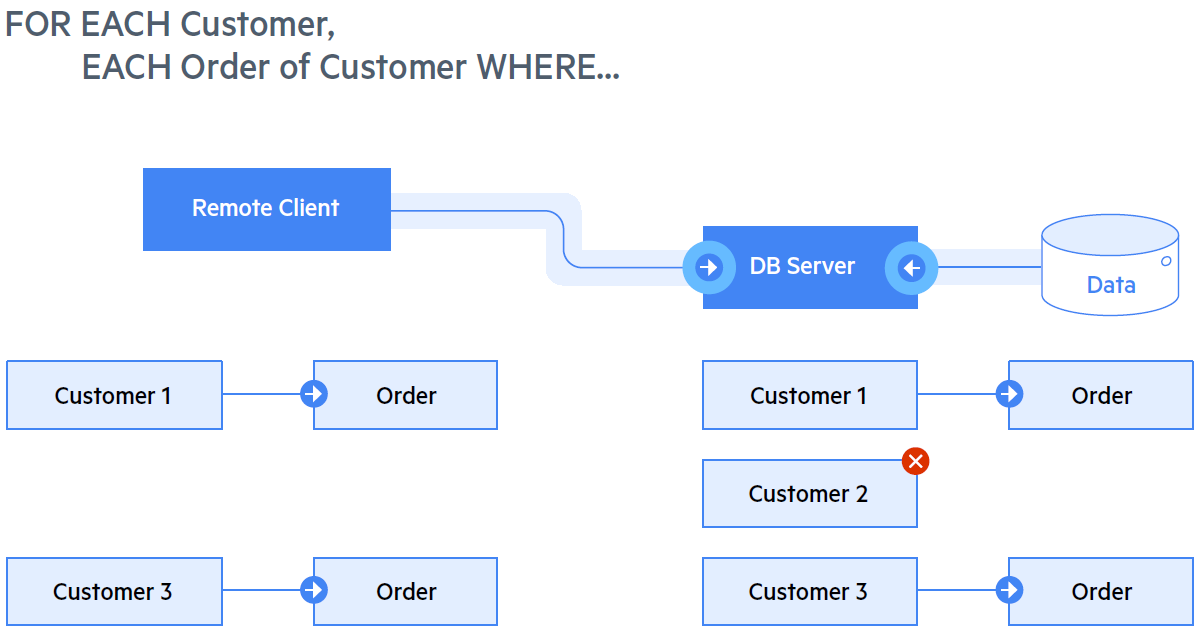
Для использования этой функции не требуется изменений в существующем коде ABL, который выполняет соединения. Тем не менее, запрос должен соответствовать определенным критериям. В версии OpenEdge 12.0, используемой в тесте производительности, существовали следующие ограничения, которые следует учитывать для SSJ:
- Запрос должен быть выполнен оператором «FOR EACH».
- Все таблицы, участвующие в объединении, должны принадлежать одной базе данных.
- Объединение должно включать не более десяти таблиц.
- В описании запроса должна использоваться только локировка NO-LOCK.
- Запрос не должен использовать LEFT-OUTER-JOINS.
- Запрос не должен использовать конструкции, которые выполняются на клиенте (например, пользовательские функции).
- Используется MTDBS.
Со времени выпуска OpenEdge 12.0 этот список был расширен дополнительными конструкциями. Поэтому с каждым новым выпуском OpenEdge 12 смотрите раздел «What’s New» в документации к этой версии чтобы найти дополнительные критерии и типы запросов, которые могут быть использованы для SSJ.
Понимая технологию SSJ, можно понять, почему для SSJ требуется MTDBS чтобы обеспечить ожидаемый результат для удалённых клиентов. Если однопоточный сервер будет занят обработкой большого запроса для отдельного удалённого клиента, то запросы всех остальных удалённых клиентов, обслуживаемых этим сервером, должны будут ждать завершения обслуживания этого большого запроса.
Активация новых функций
BHT
Количество латчей BHT может быть изменено с помощью параметра старта базы данных -latchHashFactor. По умолчанию этот параметр имеет значение 10% от размера хэш-таблицы -hash. Значение параметра не может быть изменено онлайн.
MTDBS
MTDBS включается путём установки параметра -threadedServer 1 во время старта базы данных. Он включён по умолчанию и может быть по-разному установлен для каждого логин-брокера (вторичного брокера).
Для MTDBS используется новый процесс с именем _mtprosrv вместо _mprosrv, который автоматический создаётся брокером после старта с параметром -threadedServer.
В promon, в виртуальных системы таблицах (VST) и в журнале базы данных (.lg) после включения MTDBS можно увидеть новый тип серверного пользователя TSRV вместо SRV.
MTDBS поддерживает все существующие параметра старта -Mi, -Ma и -Mn точно так же как и однопоточные серверы.
Изменились системные требования для использования MTDBS. Убедитесь, что ulimits установлен соответствующим образом, чтобы для MTDBS было достаточно «max user processes» (потоки) из расчёта «-Ma + 3». MTDBS также требуется больший размер стека и дополнительная виртуальная память, поэтому соответствующие ulimits также должны быть установлены в зависимости от ситуации. Каждому потоку потребуется около 1 Мб дополнительной памяти.
Все потоки MTDBS используют одни и те же файловые дескрипторы базы данных, поэтому для доступа к базе данных никаких дополнительных дескрипторов не требуется.
По-прежнему существует только один открытый сокет на каждое удалённое соединение «-Ma + 1» для каждого многопоточного сервера. То же относится и к однопоточным серверам.
SSJ
SSJ включается параметром старта базы данных -SSJ 1. Он включён по умолчанию и может быть по-разному установлен для каждого логин-брокера (вторичного брокера).
Включение SSJ допускается только в том случае, если брокер работает с параметром старта -threadedServer 1.
Убедиться в том, что запрос выполняется в режиме SSJ можно путём включения журнала клиентского логирования со следующими параметрами: -logentrytypes QryInfo, -logginglevel 3. В этом случае журнал будет содержать информацию о количестве передаваемых записей. А скорость передачи данных между клиентом и сервером можно посмотреть в promon на экране Servers.
Предварительная информация о тестировании
Выполненные тест был призван продемонстрировать улучшение производительности по мере последовательного включения трёх описанных выше улучшений в OpenEdge 12. Поэтому был использован более Общий тест, а не три различных теста, каждый из которых демонстрировал бы определенное улучшение. Например, тест с высоким конфликтом блокировки записей или тест в медленной сети продемонстрирует определенное улучшение, но не будет повторяться или применяться во всех трёх улучшениях.
Для улучшения повторяемости была выбрана локальная сеть. Ожидается, что в реальных испытаниях затраты производительности сетевого ввода-вывода только улучшат результаты.
Выбранная рабочая нагрузка заключалась в запуске X CS соединений между X серверами со следующими параметрами запуска.
Основные параметра:
- B 25000 (обеспечивает 100% коэффициент попадания в буферный пул)
- L 25000
- TXERetryLimit 500
- aibufs 800
- bibufs 800
- hashLatchFactor 100
- lruskips 200
- lru2skips 200
- nap 1
- napmax 24
- pica 10000
- pwscan 2048
- pwwmax 512
- pwqdelay 1
- semsets 200
- spin 25000
Сетевые параметры:
- H localhost
- Mi 20
- Ma 20
- Mm 32600
- Mn 50
- prefetchDelay
- prefetchFactor 100
- prefetchNumRecs 100
- prefetchPriority 1
Тест
Среда:
- Linux
- #1 SMP Thu Jan 4 17:31:22 UTC 2018
- 2.6.32-696.18.7.el6.x86_64
- Architecture: x86_64
- CPU(s): 24
- Thread(s) per core: 2
- Core(s) per socket: 6
- Socket(s): 2
- NUMA node(s): 2
- Model name: Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz
Версии OpenEdge:
- 12.1 против 11.7.4.
Конфигурация базы данных и распределение данных:
Типичная высокая нагрузка на чтение, чтение 250 000 записей в секунду для 150 конкурентных пользователей на 8 серверах БД.
Информация о запросе:
Объединение 7 таблиц, представление 25% записей, фильтрация записей варьируется в пределах 75% между таблицами.
FOR EACH Table1 NO-LOCK,
EACH Table2 NO-LOCK OF Table1,
EACH Table3 NO-LOCK WHERE Table3.Percent_100 = Table2.Num_key2,
EACH Table4 NO-LOCK OF Table3,
EACH Table5 NO-LOCK WHERE Table5.Percent_75 = Table4.Num_Key4,
EACH Table6 NO-LOCK OF Table5,
EACH Table7 NO-LOCK WHERE Table7.Percent_50 = Table6.Num_Key6.
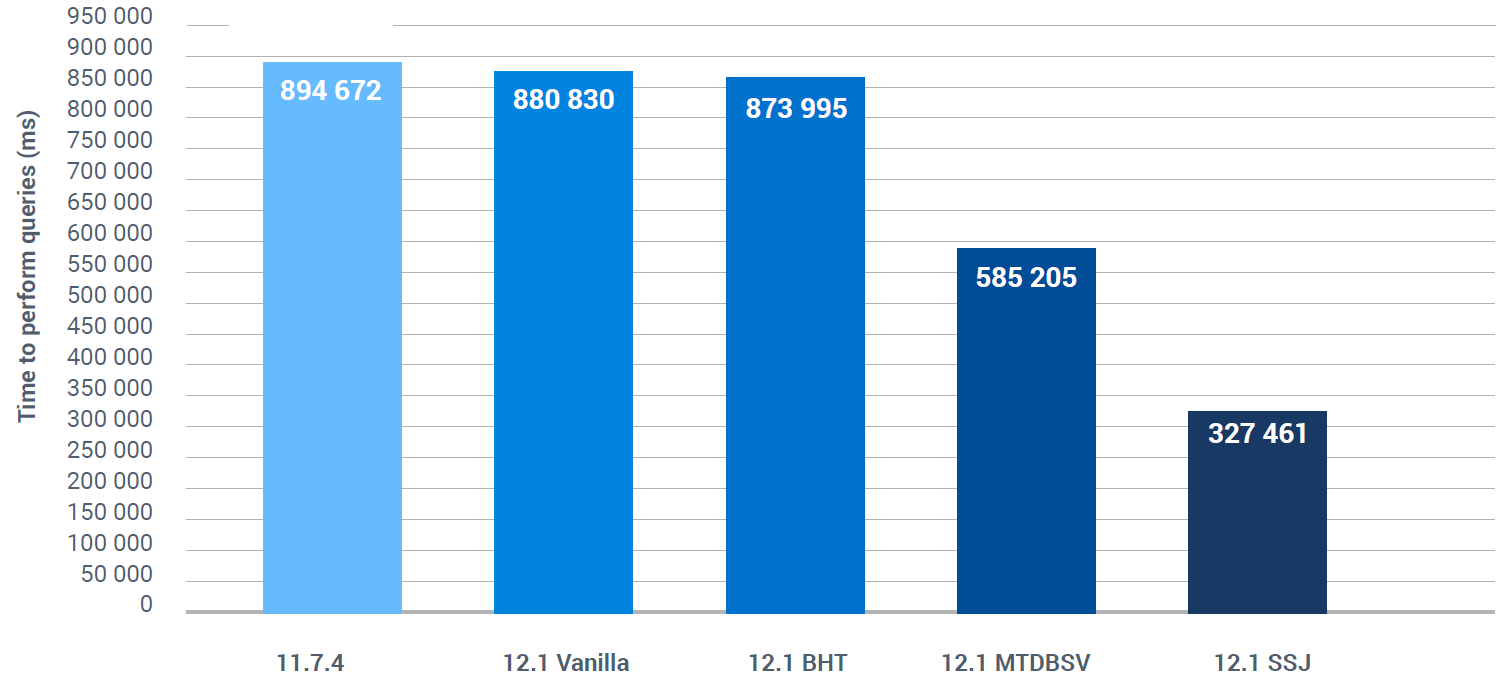
Результат для BHT
Улучшение производительности на ~ 3%.
Здесь следует понимать, что в качестве измеряемого улучшения использовался сервер без потоков, поэтому для 150 пользователей был обеспечен параллелизм только в 8 потоков, поскольку MTDBS не был включён в тестирование. Трудно сказать, насколько улучшение производительности, обеспечиваемое MTDBS, можно отнести на счёт улучшений BHT.
Этот тест следует повторить с параметрами -Mi 1, -Ma 1, -Mn 150 для увеличения параллелизма. Однако это нельзя использовать для демонстрации пошагового эффекта добавления каждой из трёх функций по очереди.
Результат для MTDBS
Помимо латчей BHT, MTDBS улучшил производительность на 35%.
Результат для SSJ
Помимо латчей BHT и MTDBS, SSJ улучшил производительность дополнительно на 44%, что в общей сложности означает, что для выполнения одних и тех же операций с доступом по локальной сети в OpenEdge 12 необходимо на 63% времени меньше.
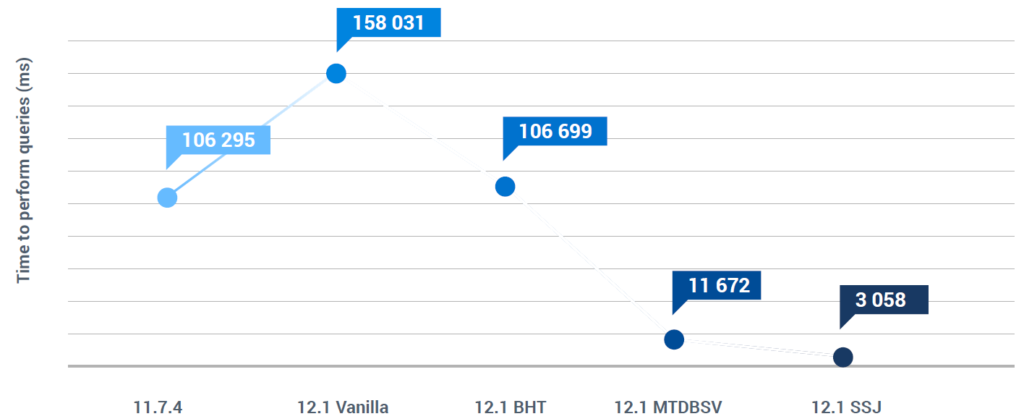
Напомним, что для достижения 100% уменьшения времени выполнения результат SSJ должен быть равен 0. Однако мы можем сказать, что в отношении OpenEdge 11.7.4 конечный результат этого тестирования зафиксировал факт того, что OpenEdge 12 необходимо примерно треть времени запуска, чем это было ранее. Это видно из результатов, представленных на Рис.5. Повышение производительности при использовании SSJ увеличивается по мере увеличения задержки в сети, например, в реальном развёртывании широкополосной связи TCP с медленными проводами и маршрутизаторами, в отличие от того, когда все работает на локальном хосте.
Стандартное отклонение, представленное на рис. 6, показывает, что не только улучшена производительность всей системы, но и результаты намного более последовательны для каждого пользователя при использовании MTDBS и даже более с SSJ.
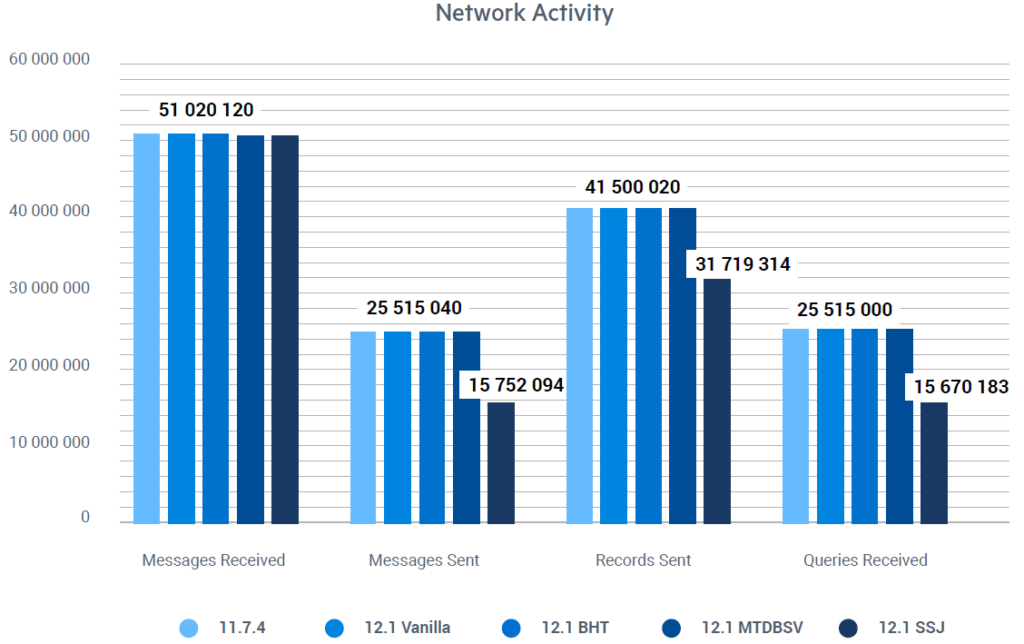
Наконец, диаграмма на рис. 7 показывает изменение сетевой активности в различных тестовых сценариях. Это изменение в сетевой активности с использованием SSJ приведёт к ещё большему повышению производительности по мере увеличения задержки в сети, то есть, если тесты будут выполнены в реальной сети, а не локальной.
Заключение
Тест и среда тестирования были выбраны не для выделения какой-либо отдельной функции, а для обеспечения общего воспроизводимого контрольного примера, который должен был показать улучшение производительности, поскольку каждая функция была наложена поверх другой. Более конкретное тестирование для выделения каждой отдельной функции не было частью этих усилий.
Большинство улучшений производительности, наблюдаемых здесь, относится к сетевому клиенту ABL/PAS for OpenEdge с доступом к базе данных OpenEdge с функциями MTDB и SSJ. Улучшение BHT, хотя здесь и не столь велико, применяется ко всем подключениям к базе данных. Несмотря на воспроизводимость тестового случая, улучшение, ожидаемое в производственных средах, зависит от того, насколько хорошо данное приложение использует каждую из этих новых функций.
Метка:Производительность


