
Объединение данных в запросах
Ранее мы рассмотрели и даже сравнили скорость извлечения данных из отдельных таблиц. Однако очень часто данные необходимо получать из двух и более связанных таблиц одновременно. Например, во время просмотра заказов (Order) мы также можем захотеть просмотреть из каких позиций состоит заказ (OrderLines).
Объединение данных в запросах (joins) формирует набор записей из нескольких связанных таблиц, которые имеют общие поля. Например, в базе данных sports2000 таблицы Customer и Order имеют общее поле CustNum.
Структурирование объединений
Повлиять на производительность запросов можно путём тщательно спланированного порядка объединений. При этом в качестве первой таблицы лучше всего использовать такую, которая будет возвращать наименьшее количество записей.
Рассмотрим два оператора, которые извлекают записи из одних и тех же таблиц Customer и Order:
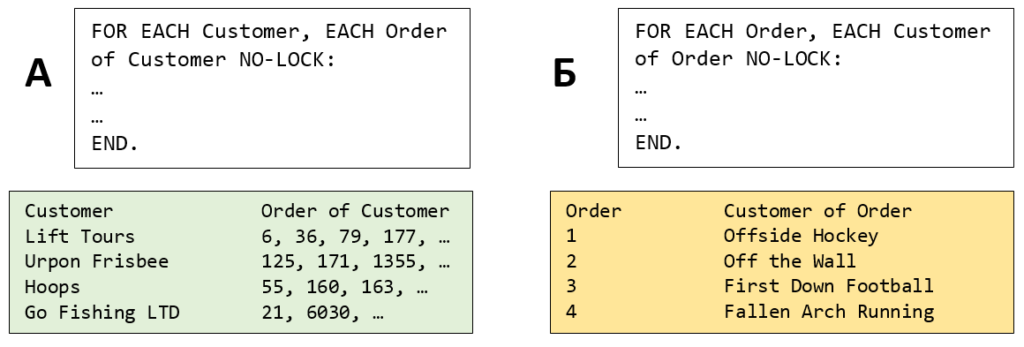
- В примере А, в первую очередь извлекаются записи Customer, а затем связанные с ними записи Order.
- В примере Б, записи Order извлекаются первыми, а затем связанные с ними записи Customer.
Обычно записей Customer меньше, чем записей Order, поэтому, скорее всего, пример А будет более эффективным, чем пример Б.
Построение эффективных объединений
Следующий пример кода отчёта демонстрирует, как выбор наилучшей последовательности объединений может повлиять на производительность. В примере для оценки времени работы каждого метода используется функция ETIME. Данные извлекаются из таблиц SalesRep, Customer и Order из базы данных Sports2000 и сохраняет их в файле отчёта.
Поскольку этот отчёт извлекает данные из трёх таблиц, существует шесть возможных комбинаций объединения.
| Объединение | Первая таблица | Вторая таблица | Третья таблица |
| Join 1 | SalesRep | Customer | Order |
| Join 2 | SalesRep | Order | Cutomer |
| Join 3 | Customer | SalesRep | Order |
| Join 4 | Customer | Order | SalesRep |
| Join 5 | Order | Customer | SalesRep |
| Join 6 | Order | SalesRep | Customer |
Примечание. В этом пример все 6 объединений выполняются из одной процедуре. Однако в реальных тестах каждое объединение должно выполняться в отдельной процедуре с перезапуском базы данных между итерациями. Кроме того, поскольку база дынных Sports2000 очень маленькая, результат сравнительного анализа может быть некорректным. Наиболее точный результат может быть получена только в базе данных размер которой сопоставим с производственной базой данных.
Итак, давайте рассмотрим сам код, который реализует все шесть объединений, описанных выше.
В первую очередь мы описываем шесть переменных для хранения шести значений прошедшего времени.
DEFINE VARIABLE iTime1 AS INTEGER NO-UNDO.
DEFINE VARIABLE iTime2 AS INTEGER NO-UNDO.
DEFINE VARIABLE iTime3 AS INTEGER NO-UNDO.
DEFINE VARIABLE iTime4 AS INTEGER NO-UNDO.
DEFINE VARIABLE iTime5 AS INTEGER NO-UNDO.
DEFINE VARIABLE iTime6 AS INTEGER NO-UNDO.
Далее описываем вывод в файл.
OUTPUT TO $WRKDIR\etime.txt.
Затем напишем шесть блоков кода, для каждого объединения.
/* 1. SalesRep, Customer, Order */
/*Инициализируем ETIME */
ETIME(YES).
/*Описываем запрос с объединением*/
FOR EACH SalesRep NO-LOCK,
EACH Customer OF SalesRep NO-LOCK,
EACH Order OF Customer NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
/*Выводим результат в файл*/
DISPLAY
"Join 1: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
/*Сохраняем прошедшее время в переменную*/
iTime1 = ETIME.
Этот процесс повторяется ещё пять раз для разных объединений:
/* 2. SalesRep, Order, Customer */
ETIME(YES).
FOR EACH SalesRep NO-LOCK,
EACH Order OF SalesRep NO-LOCK,
EACH Customer OF Order NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 2: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime2 = ETIME.
/* 3. Customer, SalesRep, Order */
ETIME(YES).
FOR EACH Customer NO-LOCK,
EACH SalesRep OF Customer NO-LOCK,
EACH Order OF Customer NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 3: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime3 = ETIME.
/* 4. Customer, Order, SalesRep */
ETIME(YES).
FOR EACH Customer NO-LOCK,
EACH Order OF Customer NO-LOCK,
EACH SalesRep OF Customer NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 4: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime4 = ETIME.
/* 5. Order, Customer, SalesRep */
ETIME(YES).
FOR EACH Order NO-LOCK ,
EACH Customer OF Order NO-LOCK,
EACH SalesRep OF Order NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 5: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime5 = ETIME.
/* 6. Order, SalesRep,Customer */
ETIME(YES).
FOR EACH Order NO-LOCK ,
EACH SalesRep OF Order NO-LOCK,
EACH Customer OF Order NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 6: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime6 = ETIME.
Когда выполнение всех блоков будет завершено, прошедшее время для каждого из них будет отображено в сообщении на экране.
MESSAGE " Join 1: SalesRep - Customer - Order: " iTime1 SKIP(1)
" Join 2: SalesRep - Order - Customer: " iTime2 SKIP(1)
" Join 3: Customer - SalesRep - Order: " iTime3 SKIP(1)
" Join 4: Customer - Order - SalesRep: " iTime4 SKIP(1)
" Join 5: Order - Customer - SalesRep: " iTime5 SKIP(1)
" Join 6: Order - SalesRep - Customer: " iTime6
VIEW-AS ALERT-BOX INFORMATION.
Выполним процедуру и посмотрим на результат. Для выполнения потребуется довольно много времени, потому что мы сканируем базу данных 6 раз.
Первое выполнение должно показать высокое время выполнения для первого объединения, независимо от того, какое объединение выполняется первым. Это вызвано кэшированием данных в памяти. Поэтому чтобы получить более точное сравнение, выполним процедуру второй раз.

Как видно, наиболее эффективное объединение это первое, которое объединяет Customer по SalesRep и Order по Customer. Это связано с тем, что записей в SalesRep меньше, чем в Customer, а в Customer меньше, чем в Order.
Выбор лучшего индекса
Не только порядок объединений, но и выбранные индексы могут повлиять на производительность.
В следующем примере три таблицы могут быть объединены или по SalesRep или по CustNum. Выбор индексов из неправильных таблиц может оказать серьёзное влияние на производительность. Давайте посмотрим, что произойдёт если выбрать неправильный индекс.
Возьмём код из предыдущей процедуры заменим в шестом объединении выборку «Customer OF Order» на «Customer OF SalesRep».
/* 6. Order, SalesRep,Customer */
ETIME(YES).
FOR EACH Order NO-LOCK ,
EACH SalesRep OF Order NO-LOCK,
/*EACH Customer OF Order NO-LOCK*/
EACH Customer OF SalesRep NO-LOCK
BREAK BY Order.SalesRep BY Customer.NAME:
DISPLAY
"Join 6: "
SalesRep.RepName
Customer.NAME
Order.OrderNum
WITH NO-BOX STREAM-IO.
END.
iTime6 = ETIME.
В оригинальном объединении Join 6 таблица Order является дочерней для таблицы Customer. Наиболее подходящим полем для их объединения будет CustNum. В таблице Customer есть индекс CustNum. А в таблице Order есть индекс CustOrder, состоящий из полей CustNum и OrderNum.
В изменённом объединение единственным общим индексом является SalesRep. Поскольку SalesRep не является подходящим индексом для получения записей Order, мы ожидаем, что выполнение этого кода займёт много времени.
Выполним этот код.

На выполнение Join 6 после изменения ушло значительно больше времени. Поэтому всего внимательно проверяйте свои индексы, чтобы убедиться в том, что вы используете наиболее подходящий для заданной цели.
Больше о влиянии индексов на производительность я расскажу в одной из следующих статей.
Структурирование объединений с критериями выбора
Если существуют ограничительные критерии выбора данных, то вероятно может потребоваться пересмотреть порядок объединений. Например, допустим, нас интересуют только заказы, которые были размещены в определённую дату. Рассмотрим следующие два оператора, которые извлекают одни и те же записи из таблиц Customer и Order.
Пример кода А:
FOR EACH Customer, EACH Order of Customer
WHERE Order.Date >= 01/01/2002 AND
Order.Date < 02/01/2002….
Пример кода Б:
FOR EACH Order
WHERE Order.Date >= 01/01/2002 AND
Order.Date < 02/01/2002,
EACH Customer of Order…
В этом случае пример кода Б более эффективен, потому что сначала извлекается подмножество заказов, а затем извлекаются клиенты, которые соответствуют выбранным заказам.
Теперь вы знаете, как в запросах происходит объединение данных из разных таблиц. Если у вас остались вопросы, то пишите их в комментариях к этой статьи.
Метка:Tuning Progress 4GL


