Разделяемая память
Следующий компонент архитектуры, который мы рассмотрим – это разделяемая память (Shared memory).
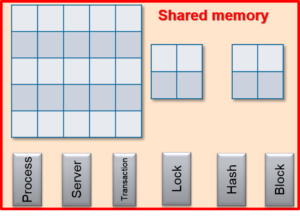
Разделяемая память представляет собой область в системной памяти компьютера. СУБД использует разделяемую память для обеспечения одновременного доступа к данным множеству пользователей. Поэтому разделяемая память базы данных существует и доступна только в многопользовательской среде.
СУБД OpenEdge использует разделяемую память для:
- хранения запрошенных пользователем данных, полученных с диска;
- изменения данных в памяти пользователями;
- сбора заметок о транзакциях базы данных;
- записи изменённых данных на диск.
Разделяемая память содержит три типа буферов, которые используются в работе СУБД:
- Буфер базы данных
- Буфер Before-image (BI)
- Буфер After-image (AI)
Буфер базы данных (database buffer) – это временная область хранения данных в памяти, которая содержит копии блоков базы данных. Все буферы базы данных расположены в области памяти, называемой Буферным пулом. Буферы базы данных предназначены для повышения производительности базы данных и снижения количества дисковых операций ввода/вывода, выступая в качестве плацдарма для всех операций с данными, такими как создание, обновление и удаление данных.
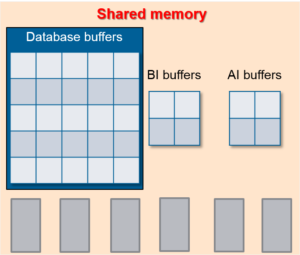
Как это работает? Представим, что мы генерируем некий отчёт. При первом исполнении отчёта СУБД считывает с диска блоки базы данных, содержащие необходимые для отчёта записи, и помещает их в буферный пул в памяти. Представим, что другой пользователь запустил другой отчёт, которому требуются аналогичные данные. СУБД, прежде чем считать данные с диска, выполнит проверку их наличия в буферном пуле. Так как во время формирования первого отчёта необходимые данные были считаны с диска в память, то СУБД обнаружит их в памяти и, не обращаясь к диску, использует для второго отчёта.
BI-буфер (Before-Image buffer) – это область временного хранения в памяти, которая используется СУБД для накопления BI-заметок о транзакциях базы данных перед их записью в BI-файл на диске. СУБД использует BI-файл для восстановления базы данных в случае возникновения каких-либо сбоев в её работе, например, после прерывания транзакции.
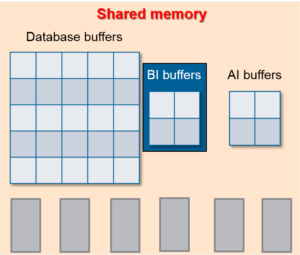
Как это работает? Допустим, мы изменяем записи в базе данных. СУБД хранит в BI-буферах все изменения в виде BI-заметок о всех транзакциях. Когда BI-буфер заполнится, СУБД запишет BI-заметки о транзакциях в BI-файл на диске. В случае сбоя в базе данных СУБД использует BI-файлы для восстановления. При следующем старте базы данных СУБД перейдёт в режим восстановления после аварии (crash recovery) и используя BI-файл в качестве ориентира, выполнит откат (отменяет) незавершённые на момент сбоя операции. Таким образом BI-буферы играют важную роль в обеспечении и защите целостности данных.
AI-буфер (After-Image buffer) – это область временного хранения в памяти, используемая для накопления AI-заметок о транзакциях базы данных перед их записью в AI-файлы на диске. СУБД OpenEdge использует AI-файлы для восстановления базы данных в случае сбоя носителя (например, в случае повреждения диска, на котором была размещена база данных). Кроме того, заметки в AI-файлах могут быть использованы для формирования горячих резервных копий базы данных механизмом Roll-forward recovery, о котором вы узнаете на уроке «Реализации Roll-fforward recovery c помощью After-Imaging».
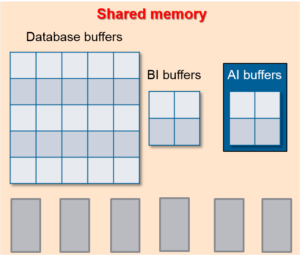
Как это работает? По мере того, как записи в базе данных изменяются, СУБД сохраняет заметки о транзакциях в AI-буферы. Когда AI-буфер заполнится, все AI-заметки из AI-буфера будут записаны в AI-файлы. В случае повреждения одного из дисков вы сможете, используя AI-файлы, восстановить все успешно завершённые транзакции вплоть до последней AI-заметки. На уроке, посвящённом механизму After-Imaging, вы узнаете, как это происходит.
СУБД OpenEdge использует несколько типов таблиц в разделяемой памяти.
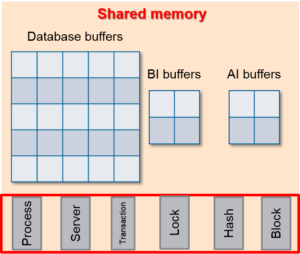
- Таблица процессов (Process table) – список всех процессов, которые в текущий момент времени имеют доступ к базе данных. Ключевыми процессами базы данных являются: брокеры, серверы, дистанционные клиенты, самообслуживающиеся клиенты.
- Таблица серверов (Server table) – содержит информацию о состоянии серверов, которые предоставляют доступ к базе данных для дистанционных клиентов.
- Таблица транзакций (Transaction table) – содержит сведения об имеющихся в текущий момент времени транзакциях в базе данных.
- Таблица локировок (Lock table) – содержит список пользователей, RECID (идентификатор записи), тип и состояние локировки для каждого запроса на локировку в базе данных. Локировка записи может иметь статус CURRENT или PENDING. Существует три типа локировок:
- NO-LOCK, вы можете читать запись в то время как другие пользователи могут получить для этой же записи локировку EXCLUSIVE-LOCK, SHARE-LOCK или NO-LOCK.
- SHARE-LOCK, вы можете прочитать запись и запросить обновление статуса локировки до EXCLUSIVE-LOCK для изменения или удаления записи, в то время как другие пользователи могут получить к этой же записи локировку SHARE-LOCK или NO-LOCK.
- EXCLUSIVE-LOCK, вы можете прочитать, изменить или удалить запись, в то время как другие пользователи в это время к этой же записи могут получить только локировку NO-LOCK.
- Хэш-таблица (Hash table) – используется для быстрого поиска буферов базы данных, содержащих требуемые записи.
- Таблица блоков (Block table) – хранит информацию о состоянии буферов.