Анализ кода и ProLint
ProLint представляет собой инструмент для автоматического статического анализа кода на OpenEdge ABL. Он читает исходные файлы кода и исследует их на соответствие стандартам и практикам программирования.
Prolint является открытым (Open Source) проектом и доступен по адресу:
http://www.oehive.org/prolint.
Для анализа кода OpenEdge ABL Ver. 10.2B и выше требуется ProLint версии 74.
ProLint выполняет только анализ кода. Никакие изменения в исходном коде не выполняются.
Для анализа кода ProLint использует библиотеку настраиваемых «правил». Каждое «правило» представляет собой определенный тест, который выполняется для исходного кода. Например:
- Каждая переменная должна быть определена с опцией NO-UNDO.
- Не используемые переменные должны быть удалены из кода.
- Каждый строковый литерал должен иметь строковые атрибуты.
- Каждая внутренняя процедура должна иметь комментарий.
- Листинг XREF не должен содержать WHOLE-INDEX или SORT-ACCESS.
Полный список правил доступен на сайте проекта (http://www.oehive.org/node/11).
Для каждого правила установлен «уровень серьезности», изменяющийся от 0 (информация) до 9 (серьезное нарушение).
Вы можете легко изменять уровень серьезности правил, в соответствии с предпочтениями Вашей компании. Вы можете также включать и выключать конкретные правила и сохранять эти установки в любом количестве «профилей» (настроенных предпочтений).
Вы также можете разрабатывать и добавлять собственные правила.
Выходная информация ProLint содержит следующие поля:
- Компилируемый файл
- Исходный файл
- Номер строки
- Описание
- Уровень серьезности
- Идентификатор правила
Выходная информация показывается в окне результатов, а также сохраняется в одном или нескольких файлов различных форматов, включая Excel и HTML.
ProLint может быть запущен различными способами:
- Как автономное приложение
- Из палитры PRO*TOOL
- Из меню Tools системы управления кодом Roundtable.
- Из Roundtable во время валидации объекта PCODE при его сохранении
- Из редактора Ed for Windows
Информация по интеграции доступна на сайте проекта.
ProLint реализован в виде набора процедур на языке ABL. Разбор кода выполняется с помощью библиотеки Proparse.NET (ранние версии – proparse.dll).
Замечание: До версии 74 информация о Proparse API (необходимая, например, для написания собственных правил) входила в дистрибутив ProLint. В версии 74 она отсутствует. Но ее можно найти на сайте разработчика Proparse: http://www.joanju.com/dist/index.html.
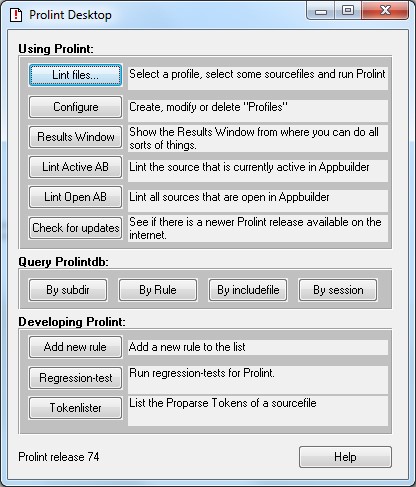
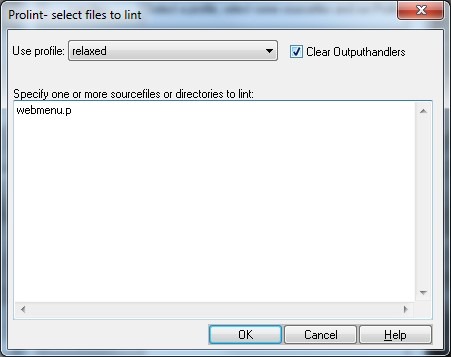
Экран десктопа ProLint приведен на Рис. 25. Для запуска проверки нажмите кнопку Lint files. Появится диалог, позволяющий ввести имена файлов для проверки и выбрать профиль правил (Рис. 26).
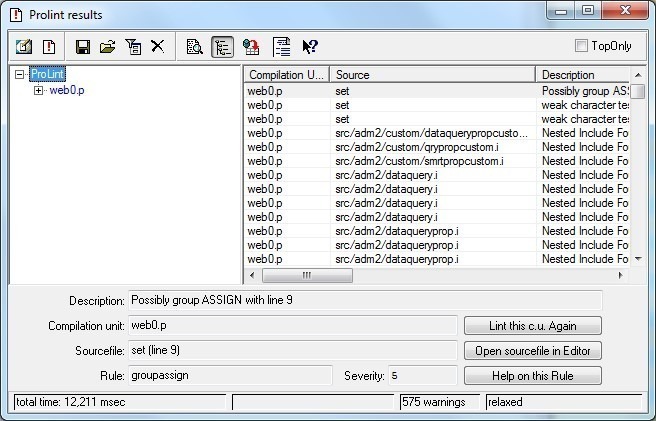
Окно результатов проверки показано на Рис. 27.
Как создать пользовательское правило
Вы можете создать пользовательское правило для проверки выполнения стандарта конкретной компании.
Вообще, набор стандартных правил, входящих в комплект поставки, достаточно велик.
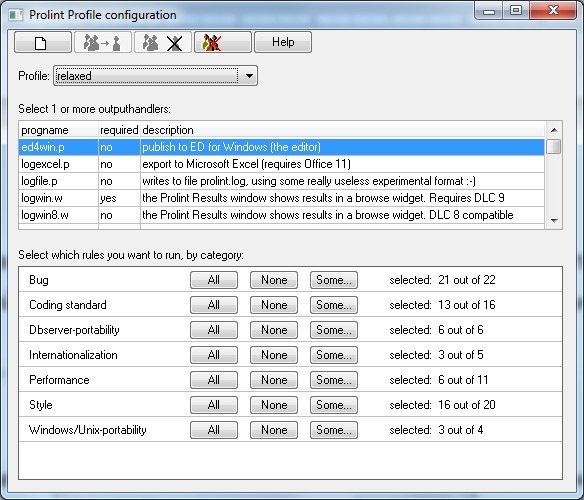
Использование различных профилей позволяет скомпоновать из существующих правил набор, подходящий именно Вам. Для управления профилями нажмите кнопку “Configure” на десктопе ProLint (Рис. 28).
Тем не менее, возникает потребность написать новое правило, или, по крайней мере, модифицировать существующее.
Если Вы создаете некоторое общее правило, то имеет смысл отправить его в проект ProLint.
Пользовательские правила подобны обычным, но располагаются в каталоге «prolint/custom/rules» вместо «prolint/rules». Содержимое каталога «prolint/custom» (и его подкаталогов) не поддерживается проектом Prolint. Другими словами, этот каталог не является частью инсталляции Prolint и не будет перезаписан при установке обновления для Prolint.
Каталог «prolint/custom» используется следующим образом:
- Каталог «prolint/custom/rules» может содержать одно или более правил и файл «rules.d».
- Файл «prolint/custom/rules/rules.d» содержит список правил, расположенных в каталоге «prolint/custom/rules». Формат этого файла идентичен формату стандартного файла «prolint/rules/rules.d».
- Каталог «prolint/custom/help/rules» содержит файлы помощи (.htm) для пользовательских правил.
ProLint импортирует файл «prolint/custom/rules/rules.d» (если он существует) и файл «prolint/rules/rules.d».
Если в пользовательском списке встречается правило с таким же идентификатором, как и правило по умолчанию, используется пользовательское правило, его описание и уровень серьезности.
Когда ProLint выполняет правило, он осуществляет поиск в следующем порядке (не зависимо от того, перечислено правило в файле «prolint/custom/rules/rules.d», или нет):
- В каталоге «prolint/custom/rules»
- В каталоге “prolint/rules”
Заметим, что ProLint не выполняет поиск скомпилированного r-кода: выполняется поиск только исходного кода (.p).
Когда в окне результатов ProLint выполняется поиск подсказки (help) для конкретного правила, сначала просматривается каталог «prolint/custom/help/rules» для HTML-файлов. Если файл не найден, используется онлайн-подсказка с сайта проекта ProLint (OpenEdge Hive).
Создание новых правил
Каждое правило представляет собой не-persistent процедуру, расположенную в каталоге «prolint/custom/rules». Проверка правила будет выполнена процедурой prolint.p, если правило имеется в списке «prolint/custom/rules/rules.d».
Файлы поддержки
Файл «prolint/rules/rules.d». Самый простой способ добавить запись в этот файл – нажать кнопку Add New Rule на десктопе ProLint.
Каждая запись файла содержит следующие поля:
- rule_id (string) – короткий уникальный идентификатор правила, должен совпадать с именем процедуры, реализующей правило.
- default severity (integer) – уровень серьезности нарушения данного правила, в диапазоне от 0 (информация) до 9 (критический).
- needproparse (logical) – yes если правило требует разбора исходного кода.
- needlisting (logical) – yes если правило требует анализа листинга компиляции (COMPILE … LISTING).
- needxref (logical) – yes если правило требует анализа файла перекрестных ссылок (COMPILE … XREF).
- needprocedurelist (logical) – yes если правило требует работы со списком всех процедур и функций, имеющихся в исходном файле. Если задано, prolint.p подготовит такой список во временной таблице.
- ignoreUIB (logical) – yes если Вы хотите подавлять предупреждения, вызванные кодом, сгенерированным в UIB/AppBuilder.
- description (string) – однострочное описание правила, показывается в окне конфигурации.
- category (string) – Категория правила. Если пустая, присваивается “Custom” (при чтении из rules.d). Диалог не позволяет ввести пустое или не предопределенное значение, но можно отредактировать файл. Не пустое не предопределенное значение в дальнейшем появится в списке конфигурации и в списке категорий в диалоге добавления правил. Если ввести «Custom» – в списке конфигурации в этой категории будут показываться как правила со значением «Custom», так и с пустым значением.
Файлы подсказки для пользователя
Каждое правило должно иметь файл подсказки (help).
Для стандартных правил (поставляющихся с ProLint) подсказки хранятся на oehive.org.
Для пользовательских правил Вы можете создать файл .htm в каталоге «prolint/custom/help/rules.
Процедура правила
Файл «prolint/rules/_template.p» представляет собой шаблон для создания нового правила.
Каждое правило вызывается с некоторым набором параметров, определенных в файле {prolint/core/ruleparams.i}.
Когда правило обнаруживает оператор или ситуацию, которая требует выдачи предупреждения, должна быть вызвана процедура PublishResult.
Процедура PublishResult реализована в prolint/core/lintsuper.p, которая является супер-процедурой для всех правил.
Поиск узлов в дереве разбора
Существуют два основных способа поиска узлов в дереве разбора, созданном proparse:
- Используя рекурсивную процедуру searchNodeTree (реализована в lintsuper.p). В большинстве случаев эта процедура слишком медленная.
- Используя запосы proparse-queries, реализованные в процедуре searchNodeQueries (в lintsuper.p).
Обе процедуры идентичны по параметрам, так что Вы имеете возможность выбирать наиболее подходящую, в зависимости от скорости работы. В качестве альтернативы может быть использован вызов процедуры searchNode (также в lintsuper.p), которая вызовет либо searchNodeTree, либо searchNodeQueries, сделав выбор за Вас.
Параметры процедур searchNode*:
- input startnode (integer) – узел дерева, поиск будет ограничен потомками этого узла
- input callback (character) – имя внутренней процедуры в процедуре правила. Эта процедура будет вызвана, когда будет найден соответствующий узел (но узлы, для которых установлен атрибут pragma_number, будут пропущены).
- input NodeTypesToInspect (character) – разделенный запятыми список типов узлов для поиска.
Примеры типов узлов: VARIABLE, BROWSE, TEMPTABLE.
Пример реализации правила
Задача: Выявить ошибки в предварительном объявлении функции, например:
FUNCTION contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR) FORWARDS.
FORWARDS и RETURN хотя и допускаются компилятором ABL, но не документированы и, например, не поддерживается Эклипсом. Мы хотим чтобы правило выдавало предупреждение для таких конструкций.
Вначале нам необходимо выработать стратегию поиска. В данном случае мы можем заметить, что искомая проблема может встретиться только при объявлении функции, то есть группа операторов обязательно будет начинаться с ключевого слова FUNCTION.
Начинаем писать правило:
{prolint/core/ruleparams.i}
RUN searchNode (hTopnode, /* "Program_root" node */
"InspectNode":U, /* name of callback procedure */
"FUNCTION":U). /* list of nodetypes to search */
RETURN.
Здесь ruleparams.i – обязательный для каждого правила инклюд. Процедура searchNode определяет границы поиска, в данном случае мы ищем во всей программе, поэтому первый параметр hTopnode. InspectNode – имя процедуры в которой реально будет проходить поиск. Третий параметр определяет ключевое слово (тип узла) при нахождении которого будет вызываться InspectNode.
Создаем процедуру InspectNode.
PROCEDURE InspectNode : /* InspectNode is where the actual rule is implemented */ DEFINE INPUT PARAMETER piTheNode AS INTEGER NO-UNDO. DEFINE OUTPUT PARAMETER pbAbortSearch AS LOGICAL NO-UNDO INITIAL NO. DEFINE OUTPUT PARAMETER pbSearchChildren AS LOGICAL NO-UNDO INITIAL NO. END PROCEDURE. /* InspectNode */
Изначально указатель узла, который передается параметром piTheNode, стоит на FUNCTION:
[piTheNode]
|
FUNCTION
contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR) FORWARDS.
Имя функции является дочерним относительно ключевого слова FUNCTION. Для перехода к имени функции используем parserNodeFirstChild.
ASSIGN
liChild = parserGetHandle()
lcChildType = parserNodeFirstChild(piTheNode,liChild)
lcFunctionName = parserGetNodeText(liChild).
Обратите внимание, мы создали указатель liChild с помощью метода parserGetHandle(). В конце процедуры его необходимо освободить.
Функция parserNodeFirstChild переместит указатель liChild на первый дочерний узел узла piTheNode. Таким образом, мы получим следующую картину
[piTheNode] [liChild]
| |
FUNCTION |
contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR) FORWARDS.
Имя функции сохраняем в переменной lcFunctionName, оно пригодится при выдаче сообщения.
Теперь нам надо переместиться к следующему узлу. Используем метод parserNodeNextSibling. Он перепозиционирует указатель liChild на следующий узел и возвращает тип узла. Текст узла получаем с помощью parserGetNodeText:
lcChildType = parserNodeNextSibling(liChild,liChild). lcReturnsText = parserGetNodeText(liChild).
[piTheNode] [liChild]
| |
FUNCTION |
contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR) FORWARDS.
Итак, мы добрались до узла, который требует проверки, нам надо убедиться, что этот узел имеет текст RETURNS.
IF lcReturnsText BEGINS "RETURN" THEN
DO:
IF lcReturnsText = "RETURN" THEN
lbReturnFound = YES.
Если текст не начинается с RETURN, то мы столкнулись с неизвестной нам ситуацией и дальнейшее выполнение правила не имеет смысла. Если текст равен RETURN, то мы выявили уязвимость. Сохраним этот факт в логической переменной и продолжим обход кода.
FORWARDS-LOOP:
DO WHILE lcChildType > "":
ASSIGN
lcChildType = parserNodeNextSibling(liChild,liChild)
lcNodeText = parserGetNodeText(liChild).
IF lcChildType = "LEXCOLON"
OR lcChildType = "PERIOD"
THEN
LEAVE FORWARDS-LOOP.
IF lcNodeText BEGINS "FORWARD" THEN
DO:
IF lcNodeText = "FORWARDS" THEN
lbForwardsFound = YES.
LEAVE FORWARDS-LOOP.
END.
END.
Указатель перемещаем с помощью parserNodeNextSibling, текст узла сохраняем в переменной lcNodeText с помощью parserGetNodeText. Если мы встретили тип узла точка или двоеточие, то предварительное объявление функции закончено, например, как в этом случае:
[piTheNode] [liChild]
| |
FUNCTION |
contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR):
Мы прерываем обход дерева, поскольку дальнейший код не имеет отношения к объявлению функции.
Если же мы нашли узел с текстом FORWARDS, например как здесь:
[piTheNode] [liChild]
| |
FUNCTION |
contractUsesSections RETURN LOGICAL PRIVATE (INPUT pcContract AS CHAR) FORWARDS.
то запоминаем это в логической переменной. Итак, поиск окончен, осталось сформировать сообщение об ошибке.
IF lbReturnFound AND NOT lbForwardsFound THEN
lcWarningText = SUBSTITUTE
("Use RETURNS instead of RETURN in &1 function declaration",
lcFunctionName).
IF lbForwardsFound AND NOT lbReturnFound THEN
lcWarningText = SUBSTITUTE
("Use FORWARD instead of FORWARDS in &1 function declaration",
lcFunctionName).
IF lbForwardsFound AND lbReturnFound THEN
lcWarningText = SUBSTITUTE
("Use FORWARD instead of FORWARDS; RETURNS instead of RETURN in &1"
+ " function declaration", lcFunctionName).
Для публикации предупреждения используется процедура PublishResult. Параметры процедуры:
Compilationunit – имя скомпилированной процедуры, оно доступно по умолчанию.
parserGetNodeFilename(piTheNode) – имя файла, в строке которого содержался исходный узел (это может быть инклюд, например). piTheNode указывает на узел который содержит ключевое слово FUNCTION.
parserGetNodeLine(piTheNode)- номер строки исходного узла (ключевое слово FUNCTION)
lcWarningText – текст предупреждения который мы сформировали
rule_id – ID правила
Ну и в самом конце не забываем освободить указатель liChild, piTheNode будет освобожден автоматически. Иначе будут проблемы с утечкой памяти.
parserReleaseHandle(liChild).
Полный код правила приведен в (Программа 70).
Программа 70. Пример правила ProLint
/* ------------------------------------------------------------------------
file : prolint/rules/custom/forwarddef.p
by : Yuri Solodkin
purpose : Reports wrong forward function definitions
-----------------------------------------------------------------------------
Copyright (C) 2009 Yuri Solodkin
------------------------------------------------------------------------ */
{prolint/core/ruleparams.i}
RUN searchNode (hTopnode, /* "Program_root" node */
"InspectNode":U, /* name of callback procedure */
"FUNCTION":U). /* list of nodetypes to search */
RETURN.
PROCEDURE InspectNode :
/* InspectNode is where the actual rule is implemented */
DEFINE INPUT PARAMETER piTheNode AS INTEGER NO-UNDO.
DEFINE OUTPUT PARAMETER pbAbortSearch AS LOGICAL NO-UNDO INITIAL NO.
DEFINE OUTPUT PARAMETER pbSearchChildren AS LOGICAL NO-UNDO INITIAL NO.
DEF VAR liChild AS INTEGER NO-UNDO.
DEF VAR lcChildType AS CHAR NO-UNDO.
DEF VAR lcFunctionName AS CHAR NO-UNDO.
DEF VAR lcReturnsText AS CHAR NO-UNDO.
DEF VAR lcNodeText AS CHAR NO-UNDO.
DEF VAR lcWarningText AS CHAR NO-UNDO.
DEF VAR i AS INTEGER NO-UNDO.
DEF VAR lbReturnFound AS LOGICAL NO-UNDO INIT NO.
DEF VAR lbForwardsFound AS LOGICAL NO-UNDO INIT NO.
ASSIGN
liChild = parserGetHandle()
lcChildType = parserNodeFirstChild(piTheNode,liChild)
lcFunctionName = parserGetNodeText(liChild).
/* next sibling is return or returns */
lcChildType = parserNodeNextSibling(liChild,liChild).
lcReturnsText = parserGetNodeText(liChild).
IF lcReturnsText BEGINS "RETURN" THEN
DO:
IF lcReturnsText = "RETURN" THEN
lbReturnFound = YES.
FORWARDS-LOOP:
DO WHILE lcChildType > "":
ASSIGN
lcChildType = parserNodeNextSibling(liChild,liChild)
lcNodeText = parserGetNodeText(liChild).
IF lcChildType = "LEXCOLON"
OR lcChildType = "PERIOD"
THEN
LEAVE FORWARDS-LOOP.
IF lcNodeText BEGINS "FORWARD" THEN
DO:
IF lcNodeText = "FORWARDS" THEN
lbForwardsFound = YES.
LEAVE FORWARDS-LOOP.
END.
END.
END.
IF lbReturnFound AND NOT lbForwardsFound THEN
lcWarningText = SUBSTITUTE("Use RETURNS instead of RETURN in &1 function declaration",
lcFunctionName).
IF lbForwardsFound AND NOT lbReturnFound THEN
lcWarningText = SUBSTITUTE("Use FORWARD instead of FORWARDS in &1 function declaration",
lcFunctionName).
IF lbForwardsFound AND lbReturnFound THEN
lcWarningText = SUBSTITUTE
("Use FORWARD instead of FORWARDS; RETURNS instead of RETURN in &1 function declaration",
lcFunctionName).
IF lbReturnFound OR lbForwardsFound THEN
RUN PublishResult
(compilationunit,
parserGetNodeFilename(piTheNode),
parserGetNodeLine(piTheNode),
lcWarningText,
rule_id).
parserReleaseHandle(liChild).
END PROCEDURE. /* InspectNode */
Устранение проблем
В заключение – пара простых рекомендаций по исправлению кода после выполнения проверки ProLint. Если Вы пишете новый код, следует сразу стремиться к выполнению всех требований стандарта и лучших практик. Это отнюдь не означает, что ваш код не вызовет никаких предупреждений. Например, вы будете получать предупреждение «wholeindex», если ваш код содержит оператор:
FOR EACH Contract NO-LOCK:
Возможно, что Вы будете получать некоторые предупреждения, даже если код правильный. Но Вы должны стремиться минимизировать число предупреждений. Все полученные предупреждения должны быть рассмотрены (и, может быть, прокомментированы).
Если Вы модифицируете существующий код, имеет смысл исправлять проблемы только в тех ветвях кода, которые Вы собираетесь протестировать. Всегда существует значительный риск что-нибудь сломать при модификации кода, поэтому не следует вносить никаких изменений в те части кода, которые не будут тестироваться.
Некоторые нарушения стандарта можно исправить без особого риска, например, правило «endtype»:
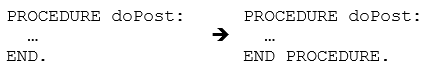
В то же время, исправление проблем блокирования или смешанных выражений AND / OR может быть сложным и потребовать тщательного тестирования.