Table Partitioning: доступ к данным секционированных таблиц
В данной статье рассматриваются сценарии, в которых может потребоваться модификация ABL-кода существующего приложения для обеспечения доступа к секционированным таблицам с использованием технологии OpenEdge Table Partitioning. Также приводятся рекомендации по разработке эффективного программного кода для работы с такими таблицами.
Следует отметить, что механизм табличного секционирования в OpenEdge функционирует прозрачно для бизнес-приложений. Тем не менее, в некоторых случаях может возникнуть необходимость внесения незначительных корректировок в существующий ABL-код для оптимизации взаимодействия с секционированными таблицами.
Обстоятельства, при которых требуется модификация программного кода
При использовании существующего ABL-приложения для взаимодействия с секционированными таблицами необходимо учитывать определенные ситуации, которые могут потребовать изменений в программном коде:
- Несоответствие ожидаемому порядку возвращаемых записей.
- Использование идентификаторов RECID и/или ROWID.
Если при работе с секционированными таблицами используется ранее созданный индекс, порядок возвращаемых записей будет идентичен порядку, который был до применения секционирования. Однако, если для секционирования таблицы был создан новый локальный индекс, и в коде не предусмотрена явная сортировка (например, через опцию BY или параметр USE-INDEX), порядок возвращаемых записей может отличаться от ожидаемого.
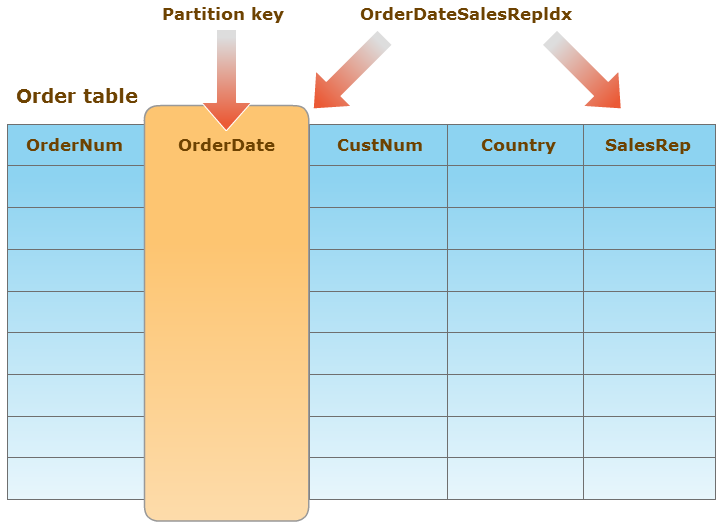
Для обеспечения сохранения порядка возвращаемых записей, аналогичного тому, который был до секционирования, необходимо внести изменения в ABL-код. Это можно сделать путем явного указания опции сортировки BY или параметра USE-INDEX с указанием нужного индекса.
Пример:
Предположим, до секционирования таблицы Order использовался индекс OrderDateSalesRepIdx, который был основан на полях OrderDate и SalesRep. Код запроса, который определял критерии поиска, но не указывал порядок сортировки, выглядел следующим образом:
FOR EACH order WHERE orderdate >= 01/01/2015 AND
orderdate <= 31/12/2015:
DISPLAY ordernum custnum orderdate salesrep.
END.
Во время выполнения этого кода OpenEdge использовал индекс OrderDateSalesRepIdx, и записи возвращались в порядке OrderDate и SalesRep.
Теперь представим, что для секционирования таблицы по диапазону с использованием поля OrderDate был создан новый локальный индекс OrderDateLocalIdx, который основан только на одном поле OrderDate.
Если необходимо, чтобы записи возвращались в том же порядке, что и раньше, необходимо явно указать порядок сортировки. Это можно сделать с помощью опции BY:
FOR EACH order WHERE orderdate >= 01/01/2015 AND
orderdate <= 31/12/2015
BY orderdate BY salesrep:
DISPLAY ordernum custnum orderdate
END.
Либо используя параметр USE-INDEX для явного указания конкретного индекса, который определит порядок сортировки возвращаемых данных:
FOR EACH order WHERE orderdate >= 01/01/2015 AND
orderdate <= 31/12/2015
USE-INDEX orderdatesalesrepidx:
DISPLAY ordernum custnum orderdate salesrep.
END.
При работе с секционированными таблицами необходимо учитывать особенности использования идентификаторов RECID и ROWID:
- Использование RECID:
– Если в коде приложения используется RECID, то его необходимо заменить на ROWID. В современных версиях OpenEdge поддержка RECID осуществляется исключительно для обеспечения обратной совместимости, однако RECID не содержат информации о секциях, что делает их использование для секционированных таблиц невозможным. Например, если приложение сохраняет или использует RECID для доступа к конкретной записи в различные моменты времени или в ином контексте, это больше не будет функционировать для секционированных таблиц. - Использование ROWID:
– Если приложение хранит ROWID и при этом запись изменяется таким образом, что она перемещается в другую секцию (например, при изменении адреса, если таблица секционируется по полю City), то необходимо предусмотреть дополнительный код для обработки этой ситуации и обновления хранимого значения ROWID. Это связано с тем, что при перемещении записи из одной секции в другую ее ROWID изменяется.
Доступ к данным
Вы можете повысить производительность системы за счёт использования табличного секционирования. Для этого необходимо адаптировать операции CRUD (Create, Read, Update, Delete) таким образом, чтобы они обращались только к тем данным, которые необходимы для конкретного запроса. OpenEdge автоматически фильтрует секции, не содержащие релевантных данных для запроса, что известно как partition pruning (отсечение секций). Данный процесс оптимизации выполняется каждый раз, когда предикат запроса в предложении WHERE использует локальный индекс для фильтрации данных. Применение отсечения секций существенно повышает эффективность запросов и общую производительность приложения.
FOR EACH order WHERE orderdate >= 01/10/2014 AND
orderdate <= 31/12/2014:
DISPLAY ordernum custnum orderdate salesrep.
END.
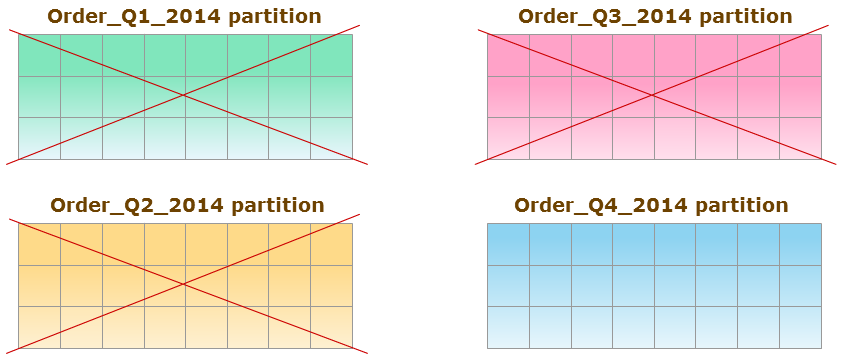
Чтение записей
Существуют различные методы доступа к данным из секционированных таблиц:
- Использование локальных индексов с функцией отсечения секций;
- Применение полного сканирования таблицы (TABLE-SCAN) с отсечением секций;
- Использование глобальных индексов в запросах к целой таблице.
Использование локальных индексов с функцией отсечения секций
Для оптимизации запросов с применением локальных индексов и функции отсечения секций рекомендуется соблюдать следующие принципы:
- В случае секционирования по списку, когда каждая секция определяется конкретным дискретным значением ключа, в выражениях WHERE необходимо использовать условие равенства.
- Для таблиц с секционированием по диапазону более эффективно применять условия сравнения «меньше чем или равно» и «больше чем или равно», а не просто «меньше чем» и «больше чем».
- В выражениях WHERE предикаты, соответствующие секционному ключу, следует указывать первыми.
- При использовании подсекционирования (например, list-list, list-range) необходимо учитывать порядок расположения секционных столбцов в локальном индексе. Поля в предикатах запроса должны быть организованы в том же порядке, что и в этом индексе.
Рассмотрим таблицу Order, которая секционирована по столбцу OrderDate. Четыре секции представляют собой финансовые кварталы с 2015 года, начиная с «Q1 2015» и заканчивая «Q4 2015». Для извлечения данных только за четвёртый квартал («Q4 2015») ABL-код должен быть написан следующим образом:
FOR EACH order WHERE orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015:
DISPLAY ordernum custnum orderdate.
END.
Во время выполнения этого кода, OpenEdge обеспечит доступ только к секции «Q4 2015», исключив остальные три секции из запроса.
Предположим, имеется запрос, возвращающий список заказов от «FedEx» за четвёртый квартал 2015 года:
FOR EACH order WHERE carrier = “FedEx” AND
orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015:
DISPLAY ordernum orderdate shipdate country.
END.
После секционирования таблицы Order по столбцу OrderDate, запрос необходимо переписать таким образом, чтобы поле OrderDate обрабатывалось первым в условии WHERE, что позволит OpenEdge выполнить отсечение секций с использованием соответствующего локального индекса:
FOR EACH order WHERE orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015 AND
carrier = “FedEx”:
DISPLAY ordernum orderdate shipdate country.
END.
Если таблица Order подсекционирована по списку и диапазону (list-range) с использованием полей Country и OrderDate, эффективным будет запрос, в котором условие WHERE сначала определяет страну, а затем диапазон дат:
FOR EACH order WHERE country = “France” AND
orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015:
DISPLAY ordernum custnum orderdate shipdate.
END.
Применение полного сканирования таблицы (TABLE-SCAN) с отсечением секций
При использовании локального индекса для чтения записей, эти записи будут извлекаться в порядке, соответствующем структуре локального индекса. Для обеспечения этого процесса, OpenEdge осуществляет доступ как к блоку данных, содержащему записи, так и к индексным блокам.
В качестве альтернативного подхода, для извлечения записей из одной или нескольких секций без использования локального индекса, можно применить ключевое слово TABLE-SCAN в запросе. При использовании TABLE-SCAN, OpenEdge осуществляет доступ только к блокам данных, исключая необходимость обращения к индексным блокам, что позволяет снизить накладные расходы на выполнение запроса. Однако, следует отметить, что при использовании TABLE-SCAN записи извлекаются в том порядке, в котором они расположены в блоках данных.
Для корректного выполнения отсечения ненужных секций при использовании TABLE-SCAN необходимо разместить секционные поля в предикатах запроса в инструкции WHERE в том же порядке, в каком они представлены в индексе. В завершение выражения WHERE следует указать ключевое слово TABLE-SCAN.
Приведем пример кода, который использует TABLE-SCAN для извлечения всех записей, где страна указана как «USA» и даты заказа попадают в диапазон четвертого квартала 2015 года:
FOR EACH order WHERE country = “USA” AND
orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015 TABLE-SCAN:
DISPLAY ordernum orderdate shipdate carrier.
END.
Выполняя данный запрос, OpenEdge сначала осуществляет отсечение ненужных секций с использованием предикатов Country и OrderDate. Затем, из оставшейся секции извлекаются все записи без обращения к локальному индексу. Следует отметить, что возвращаемые записи будут упорядочены в соответствии с их расположением в блоках данных.
Использование глобальных индексов в запросах к целой таблице
Для извлечения записей из всей таблицы рекомендуется использовать глобальный индекс. Глобальные индексы представляют собой аналоги индексов, применяемых в несекционированных таблицах. В связи с этим, система OpenEdge применяет к ним идентичные правила выбора и использования индекса.
- Если требуется извлечь все записи из таблицы без указания условий в предложении WHERE, сортировки с использованием опции BY или применения параметра USE-INDEX, система OpenEdge задействует первичный индекс для выполнения этой операции.
- Если в предложении WHERE указано условие, и существует индекс, основанный на соответствующих предикатах запроса, система OpenEdge применит этот индекс для оптимизации выборки данных.
Пример:
Предположим, что таблица Order разделена на секции по списку и диапазону (list-range) на основе столбцов Country и OrderDate. Таблица также имеет первичный ключ OrderNumIdx, который определен на столбце OrderNum.
Следующий фрагмент кода на языке ABL извлечет все записи из таблицы с использованием индекса OrderNumIdx:
FOR EACH order: DISPLAY ordernum custnum orderdate. END.
Если в таблице Order имеется глобальный индекс OrderStatusIdx, который определен на столбце OrderStatus, то следующий код, используя этот индекс, извлечет все записи со статусом заказа, равным “Ordered”:
FOR EACH order WHERE orderstatus = "Ordered": DISPLAY ordernum custnum orderdate. END.
Создание записей
Процедура создания записи в секционированной таблице идентична процессу создания записи в несекционированной таблице, за исключением того, что запись не может быть создана в секции, обозначенной как “только для чтения” (read-only).
Тем не менее, существует определенное требование, касающееся заполнения полей при создании записи в секционированной таблице.
При создании записи необходимо сразу указать значения для всех полей, составляющих ключ секции. Эта информация необходима для системы OpenEdge для идентификации соответствующей секции и сохранения записи. Таким образом, значения секционных полей должны быть определены до фактического создания записи.
Использование отдельного оператора ASSIGN, который предписывает OpenEdge физически создать запись в базе данных до указания значений секционных столбцов, приведет к возникновению ошибки. В связи с этим рекомендуется использовать единый оператор ASSIGN для задания всех значений в необходимых полях, включая секционные, и размещать этот оператор непосредственно после оператора CREATE.
Значения для секционированных полей могут быть присвоены как непосредственно через ABL-код, так и путем установки инициализирующих значений на уровне схемы базы данных. Существует три метода для определения значений секционированных полей до создания записи:
- На уровне схемы базы данных, посредством задания значений по умолчанию.
- С использованием табличного триггера базы данных.
- С помощью оператора ASSIGN.
Пример.
Допустим, что таблица Order является подсекционированной по списку и диапазону (list-range) на основе столбцов Country и OrderDate. Таблица имеет первичный индекс, основанный на столбце OrderNum, а значения по умолчанию для полей Country и OrderDate являются неопределенными (?).
Следующий код иллюстрирует присвоение необходимых значений в одном операторе ASSIGN:
CREATE order.
ASSIGN ordernum = NEXT-VALUE(next-ord-num)
country = “USA”
orderdate = TODAY.
Что произойдёт если секционному полю не будет присвоено значение в момент создания записи?
В следующем коде исключим из оператора ASSIGN присвоение значений полям Country и OrderDate:
CREATE order. ASSIGN ordernum = NEXT-VALUE(next-ord-num).
Выполним этот код.
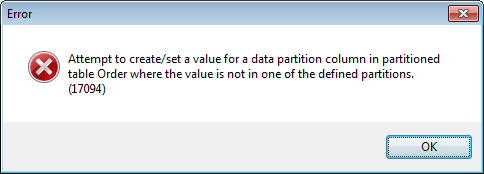
В процессе выполнения программы была зафиксирована ошибка времени выполнения. Система OpenEdge не смогла корректно идентифицировать секцию для создания записи вследствие того, что из программного кода были удалены операции присваивания значений секционным полям Country и OrderDate. В результате, значения этих полей по умолчанию принимают неопределённое состояние, обозначаемое символом “?”.
Что произойдёт, если секционному полю будет присвоено значение, для которого в таблице не создана секция?
Теперь вернём в код заполнение секционных полей Country и OrderDate, но присвоим им значения, для которых не существует секционного ключа:
CREATE order.
ASSIGN ordernum = NEXT-VALUE(next-ord-num)
country = “Antarctica”
orderdate = 31/12/2026.
Выполним этот код:
В процессе выполнения возникла ошибка, аналогичная предыдущей. Причиной её возникновения стало то, что система OpenEdge не смогла корректно идентифицировать секцию для создания записи.
Изменение записей
Модификация данных в секционированной таблице осуществляется аналогично процессу в несекционированной таблице, за исключением ограничения на изменение записей в секции, обозначенной как «только для чтения» (read-only).
Модификация значения секционного ключа инициирует миграцию записи в другую секцию. Например, при изменении значения секционного ключа, определяющего диапазон, на значение, выходящее за пределы текущего диапазона секции, запись перемещается в соответствующую новую секцию.
Процесс миграции включает дополнительные операции, что может повлиять на производительность системы. Эти операции включают удаление исходной записи из текущей секции, добавление модифицированной записи в новую секцию и обновление всех связанных индексов.
В некоторых случаях модификация значения секционного ключа может быть оправдана, например, при изменении региона клиента и необходимости обновления его адреса. Однако частая модификация значений секционного ключа может указывать на несоответствие текущего подхода к секционированию таблицы решаемой задаче. В таких ситуациях рекомендуется провести анализ и, при необходимости, пересмотреть архитектуру секционирования таблицы.
Пример:
Рассмотрим таблицу Order, секционированную по схеме list-range на основе столбцов Country и OrderDate. В данном примере кода изменение значения поля Carrier не приведет к миграции записи в другую секцию:
FOR EACH order WHERE country = “Germany” AND
orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015:
ASSIGN carrier = “DHL”.
END.
В качестве противоположного примера попробуем изменить поле orderdate на дату, для которой не существует секции.
FIND LAST order WHERE country = “Germany” NO-LOCK.
ASSIGN
OrderDate = 31/12/2026.
Мы снова получим ошибку с номером 17094 в процессе выполнения потому, что секции для новой даты не существует.
На основании представленных примеров можно сделать вывод о безусловной важности корректного присвоения значений, соответствующих установленным требованиям, секционным полям таблицы при создании и изменении записи.
Как избежать проблем?
Для предотвращения указанных проблем при создании и модификации записей в секционированных таблицах рекомендуется обеспечить автоматическое заполнение всех полей секционного ключа, по крайней мере, значениями по умолчанию. Это гарантирует корректное определение соответствующей секции для сохранения новой или измененной записи.
Первый подход заключается в указании значений по умолчанию в описании поля соответствующей секционированной таблицы. Эти значения будут автоматически присваиваться при создании записи. Например, для поля типа данных DATE значением по умолчанию может служить функция TODAY. Для полей типа данных INTEGER или INT64 значением по умолчанию может являться цифра 0. В случае использования указанных значений по умолчанию необходимо предусмотреть наличие соответствующих секций по умолчанию в структуре секционирования.
Например, если ключ секции включает только поле типа данных DATE, то должна существовать секция с типом RANGE, определяющая текущий период. В случае, если текущая дата составляет 27/11/2025, то секция должна быть настроена с условием, что значения в ключе секции должны быть меньше или равны 31/12/2025, что соответствует текущему году. Аналогично, если ключ секции состоит из поля типа INTEGER с значением по умолчанию 0, то необходимо предусмотреть секцию с типом LIST, где условие хранения будет равно 0, или секцию с типом RANGE, где условие хранения будет меньше или равно 0.
При таком подходе, даже если после создания записи значения полей ключа секции изменятся и запись будет перемещена в другую секцию, вероятность возникновения ошибки, связанной с отсутствием секции, будет исключена.
Второй подход предполагает использование внутреннего триггера CREATE на уровне таблицы. Применение триггеров предоставляет повышенную гибкость при формировании сложных начальных значений полей, поскольку позволяет задействовать программный код ABL для генерации необходимых значений.
Пример стандартного триггера CREATE для таблицы Order тестовой базы данных sports2000:
/***************************************************************************\ ***************************************************************************** ** ** Program: crord.p ** Descript: ** ***************************************************************************** \***************************************************************************/ TRIGGER PROCEDURE FOR Create OF Order. /* Automatically Increment Order-Number using Next-Ord-Num Sequence */ ASSIGN order.ordernum = NEXT-VALUE(NextOrdNum) /* Set Order Date to TODAY, Promise Date to 2 weeks from TODAY */ order.orderdate = TODAY order.promisedate = TODAY + 14.
Третий подход предполагает обработку номера ошибки 17094 в программном коде приложения с использованием класса Progress.Lang.SysErr.
Когда оператор ABL генерирует сообщение об ошибке и инициирует условие ERROR, виртуальная машина AVM создаёт объект класса Progress.Lang.SysError. С помощью метода GetMessageNum() данного объекта можно получить номер ошибки, что позволяет осуществить её обработку в блоке CATCH. Ниже приведён пример ABL-кода, иллюстрирующий данный подход:
DEFINE VARIABLE vOrderDate AS DATE LABEL "Дата заказа" NO-UNDO.
// Максимальный лимит попыток ввода
DEFINE VARIABLE MAX_ATTEMPTS AS INTEGER INITIAL 3.
DEFINE VARIABLE iAttemptCount AS INTEGER NO-UNDO INITIAL 0.
REPEAT WHILE iAttemptCount < MAX_ATTEMPTS:
iAttemptCount = iAttemptCount + 1.
// Запрос ввода у пользователя
UPDATE vOrderDate HELP "Введите дату заказа" WITH FRAME inputFrame.
// Проверка на пустой ввод
IF vOrderDate = ? THEN
DO:
MESSAGE "Ввод не может быть пустым. Попробуйте ещё раз." VIEW-AS ALERT-BOX ERROR.
NEXT.
END.
CREATE order.
ASSIGN
custnum = 1
ordernum = NEXT-VALUE(NextOrdNum)
orderdate = vOrderDate
NO-ERROR.
LEAVE.
CATCH eSysError AS Progress.Lang.SysError:
// Обработка конкретной ошибки 17094 (отсутствие секции)
IF eSysError:GetMessageNum(1) = 17094 THEN
DO:
MESSAGE "Отсутствует секция для таблицы ORDER и ключевого поля: " SKIP
"OrderDate = " vOrderDate "." SKIP
"Введите другое значение или обратитесь к администратору базы данных." SKIP
"Повторить?"
VIEW-AS ALERT-BOX BUTTONS RETRY-CANCEL
UPDATE lChoice AS LOGICAL.
IF NOT lChoice THEN LEAVE.
END.
ELSE // Другие ошибки — прерывание с сообщением
MESSAGE "Произошла ошибка: " eSysError:GetMessage(1) VIEW-AS ALERT-BOX ERROR.
END CATCH.
END.
// Проверка, удалось ли получить корректное значение
IF iAttemptCount >= MAX_ATTEMPTS THEN
MESSAGE "Не удалось получить корректную дату после " MAX_ATTEMPTS " попыток."
VIEW-AS ALERT-BOX ERROR.
Удаление записей
Удаление записи из секционированной таблицы выполняется так же, как и в обычной несекционированной таблице, за исключением того, что вы не можете удалить запись из секции, помеченной «только для чтения» (read-only).
Пример. Воспользуемся опять таблицей Order. Следующий пример ABL-кода выполнит удаление всех записей, созданных в четвёртом квартале 2015 года для клиента с номером 101.
FOR EACH order WHERE country = “Italy” AND
orderdate >= 01/10/2015 AND
orderdate <= 31/12/2015 AND
custnum = 101:
DELETE order.
END.
В данном примере OpenEdge сначала выполняет отсечение ненужных секций, оставляя только секцию для Италии за четвертый квартал 2015 года, а затем удаляет все записи клиента с номером 101.
Заключение
Таким образом, вы наглядно убедились, что, несмотря на прозрачную интеграцию табличного секционирования в OpenEdge для приложения, существуют определенные условия, при которых для полного использования всех возможностей OpenEdge Table Partitioning потребуется внести соответствующие изменения в программный код в соответствии с правилами, изложенными в данной статье.
Дополнительные материалы:


