Как мы создали CI\CD для депозитарной системы
Глава 1. Почему мы задумались над автоматизацией процесса разработки ПО и как это может быть полезно вам
А ещё какой процесс разработки был ранее и почему от него пришлось отказаться
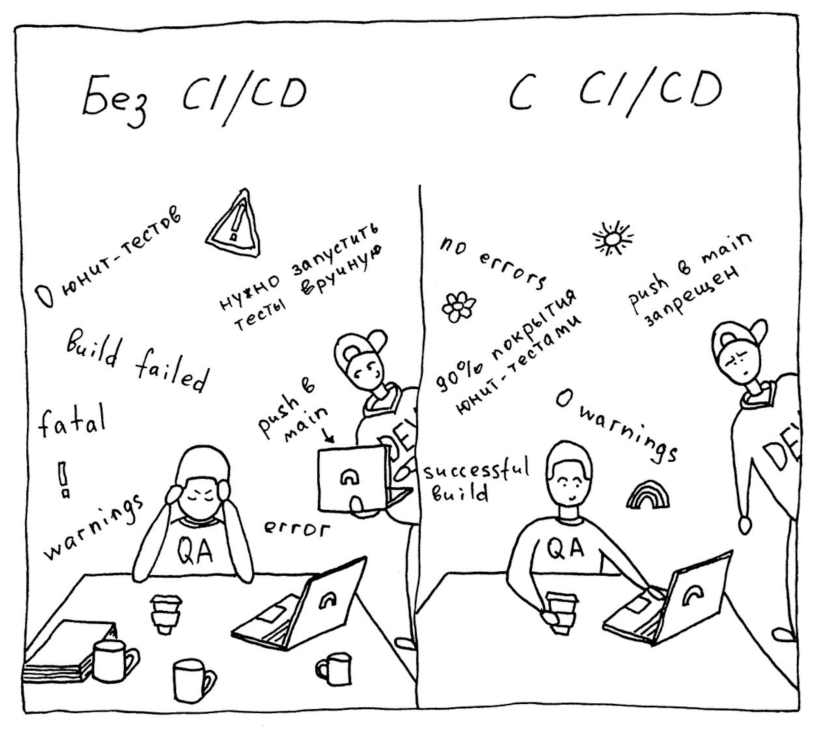
Одним из стандартных, до недавнего времени распространённых и самых простых подходов в разработке является каскадная разработка ПО (waterfall-методология). При таком подходе программисты зачастую создают код независимо друг от друга. Далее их разработки аккумулируются в один пакет для последующего релиза новой версии ПО. Стадия интеграции – последняя и зачастую самая проблемная. Выявленные на этом этапе ошибки и проблемы могут непредсказуемо задержать выход очередного релиза ПО. Это главный недостаток такого подхода в случае отсутствия автоматизации в системе разработки ПО.
Без системы контроля версий такой процесс разработки даже в небольшой команде становится проблемой. Представьте, что в вашей команде два разработчика. Они пользуются общим репозиторием (шарой), где хранится исходный код. Оба разработчика получили разные задачи, но в рамках реализации им нужно внести изменения в один и тот же исходник. Даже при эффективной коммуникации, когда коллеги это выяснили и заранее договорились о порядке работы с файлом, кому-то из них придется ждать внесения своих изменений, пока другой не внесёт свои. В результате, в большинстве случаев разработчик, который сохранил изменения последним, по незнанию стирает чужие исправления.
Кроме всего прочего, не стоит забывать про человеческий фактор – программист тоже человек, и ему присущи ошибки. Программист пишет код, сам его тестирует (хорошо, если это действительно имеет место) и сам же принимает решение о его включении в релиз. Очевидно, что при таком подходе «сюрпризы» в виде сбоев и аварий в продуктовой системе не заставят себя долго ждать. В итоге мы получаем затяжные циклы релизов с достаточно сырой функциональностью, если тестирование проекта не поставлено на рельсы (зачастую, с такой схемой работы оно вообще отсутствует или минимально).
А теперь представьте, что команда разработчиков выросла, допустим, с 2 до 5 человек. Эти неудобства перерастают в реальные проблемы по разработке кода и его объединению в релиз с последующей доставкой на продуктовый сервер. Чем больше становится проект и чем больше людей участвует в его развитии, тем больше изменений вносится в продукт и тем труднее их проверять и отслеживать. Это приводит к задержкам при подготовке и выкатке релиза, от чего страдают конечные пользователи. При этом чаще всего тестированием функциональности при таком подходе занимается минимум QA-инженеров в ручном режиме. Это означает, что большая часть функциональности тестируется или разработчиком, или кем-то из пользователей.
Именно такая картина была до недавнего времени и в нашем проекте. Вышеупомянутые проблемы послужили отправной точкой к разработке и внедрению процесса CI\CD для системы депозитарного учёта Go-DN в компании Go Invest (брокерская деятельность) . И как показало дальнейшее развитие событий, такой подход был нам крайне необходим.

Немного технических вводных о проекте
Депозитарная система Go-DN – это комплексное решение для ведения депозитарной деятельности, позволяющее вести учёт прав собственности на ценные бумаги и сделок с ними.
Система Go-DN реализована на СУБД Progress OpenEdge. Большая часть функциональности работает в схеме «клиент-сервер». Наиболее критичные процессы работают в трёхзвенной архитектуре «клиент – сервер приложений – СУБД», что позволяет максимально сокращать время работы процессов и укладываться во временные рамки SLA. Клиентская часть также реализована на Progress ABL, сервер приложений – на Progress Application Server for OpenEdge (PAS или PASOE).
Система умеет взаимодействовать со сторонними веб-сервисами, а для интеграции с другими системами имеет свои сервисы, реализованные на Progress и развёрнутые на PASOE. Go-DN умеет работать с шинами данных Kafka, IBM WebSphere MQ, Rabbit MQ и т.п.
Отдел экспертизы Progress 4GL, осуществляющий развитие системы депозитарного учёта Go-DN, состоит из 5 разработчиков. На тестирование доработок в Go-DN выделен один штатный QA. Анализ и постановку задач выполняет один аналитик. Мы работаем двухнедельными спринтами, релиз – один раз в неделю (в четверг). Два раза в неделю проводятся синхронизации с бизнесом, на которых PO планирует спринт, а участники обсуждают проблемы по тем или иным задачам. При возникновении срочных, внезапно появившихся задач вносятся изменения в планирование спринта (да-да, «прилетахи» есть и у нас).
Пять раз проверь, один раз залей: какие этапы проходит процесс разработки до прода
Немного опишем структуру нашего приложения.
У нас есть несколько сред (контуров):
- Develop – тестовый контур, песочница для разработчиков.
- Preprod – тестовый контур, БД которого каждую ночь обновляются с прода. Таким образом, имеется возможность тестирования фичей на максимально актуальных данных.
- Int – интеграционный контур, деплой в который происходит параллельно с деплоем в preprod. В отличие от последнего, int заточен под тестирование крупных проектов, в которых задействованы смежные команды компании. Поэтому обновление БД этого контура происходит только при старте очередного крупного проекта.
- Masterstaging или stage – контур для раскатки собранного для прода релиза, фактически зеркало продуктового контура.
- Prod – боевой контур, прод.
Интеграционными ветками являются develop и preprod. Функциональные ветки с доработками по разным задачам последовательно вливаются сначала в develop, а потом в preprod.
Глава 2. Краткий ликбез по CI/CD
Для тех, кто не в теме
Непрерывная интеграция (Continuous Integration, CI) – это автоматизированный процесс сборки и тестирования программного кода в разделяемом репозитории. Новые коммиты создаются изолированно. Затем они собираются и тестируются на соответствие определённым стандартам, а после – вливаются в основную ветку, соответствующую определённому контуру системы.
Обычно непрерывная интеграция сопряжена с непрерывной доставкой (Continuous Delivery, CD), когда собранные на первом этапе (CI) артефакты (исполняемый код, другие специфичные для соответствующего решения файлы) автоматически доставляются в нужный контур. Конечным этапом является деплой релиза в продуктовую систему.
Почему CI CD, а не старая методология

Выстроенный CI\CD конвейер обеспечивает множество преимуществ, среди которых:
- раннее обнаружение проблем и ошибок и их фиксация до слияния кода в целевую ветку;
- более короткие и менее напряжённые релизные циклы;
- автоматическое тестирование кода – покрытие функциональности юнит-тестами, которые исполняются при создании сборок;
- минимизация времени на поиск багов, в том числе благодаря покрытию функциональности юнит-тестами;
- быстрая автоматическая доставка ПО на целевые контуры;
- повышение эффективности коммуникаций (уведомление о дате и составе релиза, получение обратной связи по продукту);
- рост качества и скорости релизов (автотестирование охватывает все аспекты продукта, поэтому большинство ошибок и тонких мест выявляются и удаляются ещё на ранних этапах разработки);
- система контроля версий, позволяющая дать ответ по истории изменения любого исходника;
- и, самое главное: регламентированный процесс решения конфликтов при продвижении доработанного кода, а также обязательный этап ревью другим разработчиком – то есть то, ради чего и затевалась наша идея.
Где мы набили шишек или сложности реализации
В компании уже был реализован конвейер CI\CD, работающий с другой широко известной и применяемой СУБД. Несмотря на это, сложность реализации пайплайна для Go-DN заключалась в отсутствии полноценно описанных процессов для Progress OpenEdge по сборке артефактов (билда) и деплою. И если деплой специфичен для разных компаний из-за отличий инфраструктуры, то процесс сборки похож, но и его пришлось продумывать с нуля. Сложности и недостатки созданного конвейера описаны ниже в этой статье.

Жизненный цикл feature\bugfix
Итак, жизненный цикл доработок приложения выглядит следующим образом:
- В нашем проекте в системе управления задачами и проектами из user-story создаётся задача, обогащается аналитиком или экспертом и по готовности назначается на конкретного разработчика в рамках планирования спринта.
- После анализа задачи программист приступает к реализации: создаёт изменения в среде разработки и оформляет их в Git в виде коммитов отдельно заведённого для задачи бранча (функциональной ветки). Вся работа ведётся в локальном репозитории, по умолчанию подключенном к develop-контуру. При этом в большинстве случаев для тестирования до начала продвижения доработки есть возможность подключения к другим тестовым контурам, например, к preprod, если нужна проверка на свежей, актуальной БД. Такую схему тестирования можно применять для всех локальных процессов, которые не используют функциональность, вынесенную на серверы приложений.
У разработчика есть возможность прогнать unit-тесты, которые хранятся в проекте и могут помочь в процессе локального тестирования. - После того, как доработка локально проверена, разработчик продвигает её на dev-контур. В процессе создания билда для PR в develop происходит прогон всех юнит-тестов.
На данном этапе не требуется обязательное ревью (хотя это возможно, если программист делает первые шаги после онбординга или хочет запросить мнение коллег по команде). После раскатки доработки в develop можно приступать к тестированию. На этом этапе подключаются QA или коллеги из бизнес-подразделения – Депозитария. Вся переписка по тестированию ведется в рамках конкретной задачи. Если тестирование успешно пройдено, появляется комментарий с просьбой оформления задачи в релиз. При этом статус задачи изменяется разработчиком на следующий (код-ревью). Если есть замечания, то они передаются разработчику, который откатывает задачу в статус, соответствующий разработке, а не тестированию, и приступает к устранению найденных ошибок\дефектов. - Разработчик оформляет PR в preprod для продвижения доработки в preprod или int. На данном этапе кто-то из коллег, обладающий компетенциями и экспертизой, проверяет доработку соответствие принятым правилам единого стиля написания кода (соглашение по именованию, наличие запрещенных приемов и т.д.), а также обращает внимание на наличие конфликтов при создании PR и результат их решения. При этом в рамках CI\CD специальная функциональность проверяет правильность оформления PR в контур, правильность оформления комментариев к коммитам, наличие доработки в dev\preprod\int до начала сборки доработки для PR в master. Обязательное условие – назначение минимум одного разработчика в качестве ревьюера, аппрув PR всеми ревьюерами. В случае успешного прохождения код-ревью на PR в preprod ставится подтверждение, и доработка может быть смержена в preprod-ветку. После раскатки и тестирования изменений на этом контуре разработчик изменяет статус задачи на «Готово к внедрению». Если есть замечания, разработчик и ревьюер продолжают общение до их доработки и закрытия. Как правило, на это может потребоваться несколько итераций. После этого ревьюер отмечает в PR требование привести коммиты в соответствие, то есть убрать хаотично созданные (как правило, для этого требуется сквош). Программист в локальном репозитории выполняет переоформление задачи и проводит задачу в dev-контур. При успешном тестировании доработка повторно продвигается на ревью. При успешном ревью доработка вливается в preprod-ветку и раскатывается в prepod- и int-средах.
- Конечный этап продвижения доработки для разработчика – PR в master. Такие PR проверяет релиз-менеджер (RM). Функции RM выполняют разработчики команды поочерёдно в соответствии с графиком. В задачи RM перед сбором и подготовкой релиза входят те же обязанности, что и у ревьюера в prepod, причём оба этих ревью не может проводить один и тот же человек. Аналогично, сам RM не может ревьюить свои PR в master – этого не позволит система, и RM будет вынужден выбрать другого человека для ревью своей доработки. Если ревью успешно, RM помечает задачу готовой для включения в релиз. В противном случае необходимо устранить замечания и провести последовательную доставку изменений по задаче, начиная с dev-контура.
- Для инициации сбора релиза RMу помогают специальные расширения в браузере. Одно из них упрощает процессы создания релизной ветки в Git, переназначения всех фич, назначенных в релиз, в релизную ветку и заведения задачи на планируемый релиз. Всё это делается одним нажатием на кнопку расширения.
В процессе сбора релиза RM решает возможные конфликты, сливая все готовые доработки в релизную ветку. После сбора релизной ветки RM делает PR в master, который, как правило, проверяет техлид команды или эксперт из разработчиков. После мерджа релиза в master программисты могут обновить master-ветку в своих локальных репозиториях и начать разработки в новом релизном цикле. Помимо этого, билд-агент производит сборку master-ветки. Переданный билд отдаётся деплой-серверу (подробнее в разделе Выбранные инструменты), который производит деплой на Stage-контур. Этот процесс позволяет дополнительно проверить раскатку релиза на зеркале продуктового контура. Если при деплое релиза на masterstaging выявлены проблемы, RM оповещает команду разработки и инициирует поиск причин. В случае успешной раскатки релиза на stage, RM настраивает расписание автоматического деплоя на прод, указывает дату и время релиза.
При сборе релиза RM использует сгенерированный к задаче чеклист – это помогает последовательно пройти все шаги процесса. Один из последних шагов – автоматическая генерация письма на всех заинтересованных о предстоящем релизе, его составе с указанием ссылки на задачу, PO, связанной задачи и её статуса по тестированию. Эту автоматизацию позволяет осуществить ещё одно расширение. После отправки письма и отдельного уведомления в канал о релизах RM назначает задачу на сотрудника сопровождения, дополнительно уведомляя его об этом.
Глава 3. Выбранные инструменты
И почему мы взяли именно их
Мы не стали изобретать велосипед и взяли за основу уже используемое в компании решение для построения конвейера CI\CD, которое в течение многих лет отлично зарекомендовало себя. Фактически мы прототипировали уже существующий конвейер с учётом специфики СУБД Progress OpenEdge и внесли необходимые коррективы.
Для создания сборок и обеспечения непрерывной интеграции мы используем build-сервер (сервер сборки). В конвейере для Go-DN один сборочный агент.
Для автоматизации развёртывания приложения используется deploy-сервер (сервер развертывания).
В качестве инструмента, который наш build-сервер использует для общения с СУБД Progress OpenEdge и для создания артефактов сборки, используется Progress Compilation Tool (PCT). PCT разработан и сопровождается Жиллем Керре (Gilles Querret), разработчиком программного обеспечения во французской компании Riverside Software (https://github.com/Riverside-Software/pct). PCT – это инструмент на основе командной строки, который даёт возможность автоматизировать ряд задач, позволяющих выполнить действия с базами данных Progress в среде утилиты: создавать на лету базы данных Progress OpenEdge, подключаться к ним, выгружать и загружать данные, получать файл различий схемы между двумя БД, компилировать исходники с целью получения бинарного кода, запускать юнит-тесты, покрывающие функциональность системы, а также делать многое другое в автоматическом режиме. Так процесс сборки Apache Ant происходит автоматически.
Упрощённо конвейер выглядит так:
а) Программист сохраняет изменение в среде разработки, оформляет коммит в Git, отправляет свой бранч на сервер и делает пул-реквест (PR) в нужный environment (контур) системы. Важно подчеркнуть, что помимо изменений в исходниках (*.p,*.i,*.w,*.cls) разработчик вносит изменения в соответствующий df-файл БД, то есть в Git у нас затянуты структуры БД приложения.
б) Git передаёт управление build-серверу – стартует автоматическое создание билда PR.
в) В случае успешности билда PR программист передает доработку на ревью (если это PR в preprod\int) или сразу мержит доработку в dev-ветку.
г) Build-сервер стартует создание сборки соответствующей ветки, в результате чего создаётся пакет с артефактами релиза:
– скомпилированный код всего проекта приложения
– изменения в структуре БД приложения в виде инкрементальных df-файлов
– полезные программы – н-р, ant-сценарий, вызывающий progress-процедуру отключения всех remote connection пользователей от БД для монопольного доступа к её схеме. Экземпляры сервера приложений, которые также блокируют схему БД, отключаются у нас отдельным шагом в процессе деплоя релиза – об этом будет сказано в следующем разделе.
д) Build-сервер передаёт пакет с артефактами deploy-серверу.
е) Deploy-сервер осуществляет развертывание собранного релиза в соответствующей среде приложения.
При этом в связи со спецификой СУБД Progress при каждом деплое происходит проверка – содержит ли релиз изменения в схеме БД (*.df). Это необходимо для того, чтобы отключить всех Remote-пользователей, а также экземпляры сервера приложений Pacific Application Server (PAS) for OpenEdge в случае, если необходимо загрузить изменения в структуру БД.
Более детально процессы создания билдов и раскатки на целевой контур описаны в следующих двух разделах.
Алгоритм создания сборок: шаг за шагом

При создании сборок можно выделить следующие этапы:
- Инициализация среды (клонирование репозитория со скриптами автоматизации, установка параметров целевой среды для Progress 4GL, получение master-ветки для всех веток кроме master, инициализация папки артефактов)
- Проверка корректности следования процессу разработки (имени ветки, имени пул-реквеста, комментария в коммите, статуса ассоциированной задачи и доработки в интеграционных ветках в случае пул-реквеста в master, создание комментариев в PR, если есть проблемы – н-р, сообщение о необходимости ребэйза)
- Создание локальных БД для сборки (билд-сервер знает расположение БД каждой среды, копирует st-файлы БД, адаптирует их, подменяя пути к файлам БД, и на лету создаёт БД из шаблона-пустышки – в нашем случае, empty4.db – и загружает в неё структуру БД из соответствующего БД df-файла)
Пример кода в приложении 1.
- Получение изменений (diff) схемы для интеграционных веток (с помощью вызова в скрипте задачи PCTIncrementalDump происходит сравнение созданной на лету БД с соответствующей физической БД на сервере той среды, для которой готовится сборка)
Пример кода в приложении 2.
- Компиляция исходного p-кода в исполняемый бинарный r-код.
Пример кода в приложении 3.
- Запуск unit-тестов
На лету для релиза создаются пустые БД. Посредством вызова в сценарии PCTLoadData в них загружаются необходимые статичные таблицы-справочники, создаются экземпляры сущностей, необходимые для работы теста (записи о клиентах, валютах, юрисдикциях и т. д.). Запуск юнит-тестов происходит через ABLUnit-задачу.
Фактически для тестирования используется максимально изолированная среда, исключающая конфликты тестирования, возникающие при использовании статических БД с целью тестирования.
Пример кода в приложении 4.
- Формирование release-notes
- Создание релиза на deploy-сервере
- Сохранение артефактов сборки
Алгоритм деплоя (раскатки)
Процесс деплоя состоит из следующих, выполняемых последовательно шагов:
- Создание папки релиза на целевом сервере. Имя папки с релизом имеет статичное значение. Если такая директория найдена, она переименовывается в <папка_с_релизом_backup>, таким образом всегда есть последний и предыдущий релизы.
- Получение пакета от deploy-сервера.
- Определение особенностей релиза.
Скрипт определяет, есть ли в артефактах релиза изменения структуры БД (*.df), для своевременного выключения всех удаленных сессий и подключений серверов приложений, а также серверных заданий для внесения изменений в монопольном режиме. - Создание полных (full) бэкапов БД проекта (только при деплое на прод).
С глубиной хранения в 2 последних релиза сохраняются бэкапы БД перед деплоем релиза. - Создание бэкапа исполняемого кода проекта.
Директория с исполняемым кодом проекта копируется в папку, содержащую в названии дату релиза, упаковывается в архив и помещается в отдельную директорию. - Выполнение предеплой-скриптов.
Запуск в специальной шаре скриптов с маской в названии «Predeploy_контур». Сами скрипты называются по следующему правилу: Predeploy_контур_номер_название_скрипта.p, например, PreDeploy_dev_001_dep_vars_679.p
Скрипт должен быть рассчитан на неоднократное выполнение и завершаться отдачей успеха (RETURN “0”). - Отключение REMC (Remote clients).
Выполняется, если релиз содержит изменения в схемах БД (*.df). - Остановка серверных заданий (jobs) (только для сред develop и production, где они работают).
- Остановка экземпляров серверов приложений.
В проекте используется два экземпляра сервера приложений PAS. Один отвечает за работу внутренних процессов приложения, на другом развёрнуты rest-сервисы для внешнего использования. Так как агенты серверов приложений блокируют схему БД, экземпляры PAS необходимо также временно останавливать в случае внесения изменений в схему БД.
Если релиз не содержит изменений в схеме БД (*.df), то данный шаг пропускается. - Внесение изменений в схему(-ы) БД.
Выполняется, если релиз содержит изменения в схемах БД (*.df). - Создание файла-маркера на stage-контуре для определения необходимости восстановления БД с прода после релиза.
Выполняется только на stage-контуре. Наличие файла позволяет работающему на stage заданию понять, что нужно восстановить БД из последнего бэкапа с прода, так как при деплое релиза были внесены изменения в схемы(-ы) БД. - Обновление директории с исполняемым кодом.
Удаление всего исполняемого кода (*.r) и копирование из сборки релиза. - Выполнение постдеплой-скриптов.
Postdeploy_контур_номер_название_скрипта.p, например, PostDeploy_prod_015_div_vars_ACC.p
Скрипт должен быть рассчитан на неоднократное выполнение и завершаться отдачей успеха (RETURN “0”). - Старт экземпляров серверов приложений PAS.
Выполняется всегда. - Старт серверных заданий.
По json-файлу с названиями заданий происходит их последовательный запуск. Выполняется в develop- и prod-контурах. - Создание бэкапа БД, если в результате релиза были внесены изменения в схему(-ы).
Именно этот бэкап используется для восстановления на stage-контуре после релиза с изменениями в структуре БД.
Глава 4. Результаты: ради чего всё затевалось и что из этого вышло (спойлер – оно того стоило)
Мы делали так, как видели: есть достоинства и недостатки, рассказываем ниже.
Весь наш пайплайн для СУБД Progress OpenEdge мы создавали с нуля. Многие моменты автоматизировали так, как это виделось или было возможным в тот момент. Например, сразу же было решено всегда компилировать весь проект. С одной стороны, это заведомо увеличивает время, которое потребуется на создание сборки и деплой, но с другой – это идеальный и гарантированный вариант, когда в проекте нет графа зависимостей исходников (наш случай). Создание такого дерева зависимостей – это очень интересная, сложная и амбициозная задача, реализация которой безусловно сократит время создания сборок и деплоев (кстати, мы уже прорабатываем эту идею).
В качестве еще одного показательного примера можно привести кейс с решением об остановке серверов приложений в случаях, когда в релизе есть изменения структуры БД или изменения программ, которые исполняются на сервере приложений. Так как процесс CI\CD рождался для версии OpenEdge 11.7.12, мы не смогли найти действенных вариантов для этой версии, чтобы заставить агентов сервера приложений обновить свой кэш и использовать обновленные в процессе релиза версии процедур. С переходом на версию 12.2 мы смогли воспользоваться новшеством утилиты tcman – refreshagents, которое позволяет не останавливать сервер приложений и при этом обновить кэш его агентов, что опять-таки экономит время доведения изменений до целевой среды. Есть и другие нюансы, детализация которых не является целью данной статьи.
Отметим, что мы и впредь будем уделять время и ресурсы тюнингу и оптимизации получившегося CI\CD решения.

Профит от внедрения решения
Внедрение вышеописанного конвейера позволило нам автоматизировать процесс доставки доработок во все контуры нашей системы и исключить из этого процесса человеческий фактор. Также увеличилась скорость вывода новой функциональности от постановки задачи до введения в эксплуатацию. Несмотря на то, что у нас бывают замечания\ошибки, выявленные после релиза, для оперативности они устраняются ручной установкой хот-фиксов и впоследствии проведением в Git соответствующего bugfix, которые проводятся в ближайший релиз. По большей части причинами багфиксов являются или упущения в процессе тестирования, или не до конца продуманная постановка задачи.
Большая часть задач, оставшихся в списке технического долга, досталась нам в наследство со времён работы «по старинке». После внедрения CI\CD тенденция по накоплению тех. долга сошла на нет. Существующий список мы стараемся периодически разгребать в рамках спринтов, выделяя время и переключаясь с бизнес-задач на технический долг, что способствует его уменьшению.
Система контроля версий позволяет быстро увидеть суть тех или иных изменений, отследить дату внесённых изменений в исходник, а также их автора.
Внедрение в CI юнит-тестов, а также планомерное покрытие ими в первую очередь критичной функциональности, позволяет на самых ранних этапах определять тонкие места и устранять ошибки. Часто ошибки представляют собой составную матрёшку: одни ошибки содержат другие, которые включают в себя третьи и т. д. Чем больше ошибок накапливается, тем сложнее их тестировать и находить. В результате это может привести к неприятным последствиям. Между тем в CI/CD-разработке автоматизированные тесты в случае провала покажут, что именно нужно исправить. Кроме того, снижаются затраты на проведение тестирования.
В целом код стал более стабильным, что значительно повысило качество ПО. Внедрение правил оформления кода, соглашений о наименовании, best practices и запрещённых приёмов позволили провести большую работу по форматированию и рефакторингу существующего кода по общепринятым правилам, что делает более комфортной дальнейшую работу с исходным кодом.
Благодаря быстрому циклу обратной связи мы почти мгновенно можем определить, насколько качественными являются изменения в коде и функциональности продукта. При каскадном подходе в разработке ПО можно так же быстро вносить изменения в код, но без постоянных проверок выявление багов и ошибок потребует гораздо больше времени и может произойти уже после начала промышленной эксплуатации, причём таких «отложенных» багов в одном релизе может оказаться несколько.
Ложка дёгтя в бочке мёда
Перечислим недостатки реализованного нами CI\CD.
Мы осознанно делали максимально простую из возможных модель, поэтому отказались от первоначального усложнения задачи по созданию билдов, чтобы в сборку попадали только те исходники и объекты БД, которые были изменены в результате доработки или зависят от изменённых сущностей. Другими словами, текущая реализация сборок, когда внесение изменений в одну процедуру инициирует компиляцию всех исходников проекта, требует оптимизации в ближайшем будущем. Речь идёт о том, чтобы реализовать анализ зависимостей между модулями, т. е. научиться строить граф зависимостей и таким образом гибко и быстро определять, что на что ссылается и какие исходники после доработки должны быть включены в сборку. Опять же, реализация такого графа позволит определять наборы юнит-тестов, которые нужно запустить при изменении какой-либо сущности.
Например, мы изменили структуру таблицы в БД и получили список использующих её процедур и тестов, вызывающих эти процедуры. При сборке запустили не все юнит-тесты, а только набор зависимых тестов (т. к. больше ничего не меняли, при сборке PR захват в билд всего исходного кода проекта, а также запуск всех юнит-тестов кажется неоптимальным, нелогичным и громоздким решением).
Важный дисклеймер
Так как мы решили доставлять изменения в схемах БД через Git, логика всего конвейера зависит от успешности последнего деплоя. В случае, если последний деплой остановится с ошибками и есть более свежий, то старый катить нельзя, так как изменения собираются кумулятивно (при сборке билдов сравнение БД в Git происходит с физическими БД того контура, для которого создаётся сборка).
Можно ли уйти от этой зависимости – предмет дальнейшего анализа процесса с целью его оптимизации и улучшения. У нас пока нет ответа на этот вопрос.
Кроме этого, в случае изменений не в исходниках Progress 4GL (*.p, *.i, *.w, *.cls) – н-р, шаблоны Excel, или схемы xml, или графические файлы – эти файлы мы устанавливаем на сервер вручную. У нас не реализован пока деплой всего, что не является r-кодом.
Заключительная мысль
В каждом процессе и задаче всегда есть что улучшать, но в разработческих командах одной из действительно важных целей является автоматизация доставки изменений. Для повышения эффективности в личной и командной работе необходимо максимально автоматизировать всё то, что разгрузит разработчика, чтобы освободившееся время он мог потратить на свои основные и интересные ему задачи и обязанности.
Также гордо заявляем, что первая выкатка произошла 12 мая 2023 года, и с тех пор не было ни одного неудачного релиза. А полученный результат превзошел все наши ожидания.
Надеемся, что наш опыт и данная статья также будут вам полезны, будем рады вопросам, а также вашей обратной связи в комментариях! В планах у нас ещё множество доработок системы, которые мы уже активно прорабатываем на момент выпуска статьи, поэтому надеемся, что этот материал станет первым, но далеко не последним, и остаемся на связи!

Полезный словарь: термины и определения
- ПО – программное обеспечение.
- DevOps (development & operations) – методология автоматизации технологических процессов сборки, настройки и развёртывания программного обеспечения. Методология предполагает активное взаимодействие специалистов по разработке со специалистами по информационно-технологическому обслуживанию и взаимную интеграцию их технологических процессов друг в друга для обеспечения высокого качества программного продукта.
- CI\CD – одна из распространённых DevOps-практик; комбинация непрерывной интеграции (continuous integration) и непрерывного развертывания (continuous delivery или continuous deployment) ПО в процессе разработки. CI\CD объединяет разработку, тестирование и развёртывание приложений.
- SLA (service level agreement) – соглашение об уровне услуг, заключаемое между заказчиком и исполнителем, содержащее описание услуги, права и обязанности сторон и, самое главное, согласованный уровень качества предоставления данной услуги. В нашем случае заказчик – это Депозитарий (бизнес-подразделение), исполнитель – IT (Центр экспертизы Progress 4GL).
- PAS\PASOE (Progress Progress Application Server for OpenEdge) – это современный, сложный, высоко масштабируемый сервер приложений, который значительно упрощает создание, развёртывание и эксплуатацию бизнес-приложений, написанных на Progress 4GL.
- PR (pull request) – запрос на изменение кода в репозитории. В нашем проекте есть 3 типа PR: feature – фича, задача на новую функциональность; bugfix – багфикс, исправление ошибки в уже реализованной функциональности; release – доработки, включенные в релиз.
- RM (release manager) – релиз-менеджер. В нашем проекте это переходящая между разработчиками роль, которая подразумевает ревью всех PR в ветку master, подготовку релиза, его автоматическое взведение на раскатку по расписанию и передачу релизной задачи, созданной в системе управления проектами и задачами, сотруднику сопровождения.
- PO (product owner) – владелец продукта; человек, отвечающий за разработку продукта и владеющий всем массивом информации о продукте.
- Предеплой-скрипты – скрипты, написанные на Progress 4GL (*.p) и (или) файлы с данными из таблицы БД (*.d); в первом случае должны отдавать нулевой код возврата; в последнем случае скрипты должны именоваться по названию таблицы БД. Выполняются перед применением релиза. Наименование таких скриптов начинается с BeforeDeploy (BeforeDeploy*.*).
- Постдеплой-скрипты – скрипты, написанные на Progress 4GL (*.p) и (или) файлы с данными из таблицы БД (*.d); в первом случае должны отдавать нулевой код возврата; в последнем случае скрипты должны именоваться по названию таблицы БД. Выполняются после применения релиза. Наименование таких скриптов начинается с PostDeploy (PostDeploy*.*).
- Сквош – один из вариантов объединения нескольких коммитов в один.
Приложения
Приложение 1
Сценарий создания директории для структурных файлов БД
<?xml version="1.0" encoding="utf-8"?>
<project name="RECREATE FOLDER FOR LOCAL DATABASES">
<property environment="env" />
<taskdef resource="PCT.properties" />
<typedef resource="types.properties" />
<property name="dstDir" value="%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/st" />
<target name="cr_folder" description="Recreate folder for .st files">
<delete dir="${dstDir}" />
<mkdir dir="${dstDir}" />
</target>
</project>
Сценарий копирования структурных файлов БД
<?xml version="1.0" encoding="utf-8"?>
<project name="COPY STRUCTURE FILES">
<property environment="env" />
<taskdef resource="PCT.properties" />
<typedef resource="types.properties" />
<property name="dstDir" value="%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/st" />
<property name="srcDir" value="%PROGRESS_ENVIRONMENT_DB_ST_PATH%" />
<target name="copy_str" description="Copy .st files">
<copy todir="${dstDir}" overwrite="true">
<fileset dir="${srcDir}" includes="*.st"/>
</copy>
</target>
</project>
Скрипт подготовки структурных файлов
$stPath = "%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/st";
$pathFrom = [regex]::Escape("%PROGRESS_ENVIRONMENT_DB_PATH%");
$pathTo = "%PROGRESS_ENVIRONMENT_STAGE_FOLDER%";
ForEach ($File in (Get-ChildItem -Path "$stPath\*.st" -Recurse -File)) {
(Get-Content $File) -Replace $pathFrom,$pathTo |
Set-Content $File
}
Сценарий создания пустой локальной БД
<?xml version="1.0" encoding="utf-8"?>
<project name="CREATE LOCAL DATABASE">
<property environment="env" />
<taskdef resource="PCT.properties" />
<typedef resource="types.properties" />
<property name="dstDir" value="%PROGRESS_ENVIRONMENT_STAGE_FOLDER%" />
<property name="srcDir" value="%system. build.checkoutDir%/%SRC_CHECKOUT_FOLDER_NAME%/db_structure" />
<property name="stDir" value="%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/st" />
<property name="dbName" value="%PROGRESS_DB_NAME_BASE%" />
<target name="cr_loc_db" description="Create local database from .df and .st files">
<PCTCreateDatabase dbName="${dbName}" destDir="${dstDir}" schemaFile="${srcDir}/${dbName}.df" structFile="${stDir}/${dbName}.st" dlcHome="${env.DLC}" blockSize="4" cpColl="Russian" cpInternal="1251" cpStream="ibm866"/>
</target>
</project>
Приложение 2
Сценарий получения инкрементального диффа схемы при сравнении БД, созданной по df из релиза, с БД соответствующего контура
<?xml version="1.0" encoding="utf-8"?>
<project name="CREATE INCREMENTAL SCHEMA FILE">
<property environment="env" />
<taskdef resource="PCT.properties" />
<typedef resource="types.properties" />
<property name="dbDir" value="%PROGRESS_ENVIRONMENT_STAGE_FOLDER%" />
<property name="destDir" value="%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/inc" />
<property name="userName" value="%PROGRESS_ENVIRONMENT_DB_USER%" />
<property name="password" value="%PROGRESS_ENVIRONMENT_DB_PASSWORD%" />
<property name="hostName" value="%PROGRESS_ENVIRONMENT_DB_HOST%" />
<property name="dbName" value="%PROGRESS_DB_NAME_BASE%" />
<property name="dbPort" value="%PROGRESS_ENVIRONMENT_DB_PORT_BASE%" />
<target name="build" description="Create DF file">
<PCTIncrementalDump destFile="${destDir}/${dbName}.df" dlcHome="${env.DLC}" removeEmptyDFFile="true" cpInternal="1251" cpStream="ibm866" cpColl="Russian">
<SourceDb dbName="${dbName}" logicalName="${dbName}_from" dbDir="${dbDir}" singleUser="true"/>
<TargetDb dbName="${dbName}" logicalName="${dbName}_to" hostName="${hostName}" dbPort="${dbPort}" userName="${userName}" password="${password}" singleUser="false"/>
</PCTIncrementalDump>
</target>
</project>
Приложение 3
Сценарий компиляции исходных файлов всего проекта для получения r-кода будущего релиза
<?xml version="1.0" encoding="utf-8"?>
<project name="REBUILD 'EM ALL" basedir="%system. build.checkoutDir%/%SRC_CHECKOUT_FOLDER_NAME%/%SRC_CHECKOUT_FOLDER_NAME%">
<property environment="env" />
<taskdef resource="PCT.properties" />
<typedef resource="types.properties" />
<property name="dbDir" value="%PROGRESS_ENVIRONMENT_STAGE_FOLDER%" />
<property name="buildOutputDir" value="%WORKING_FOLDER%/%PROGRESS_ENVIRONMENT_STAGE_NAME%/build_output" />
<property name="repositoryDir" value="." />
<target name="build" description="build files">
<delete dir="${buildOutputDir}" />
<mkdir dir="${buildOutputDir}" />
<PCTCompile destDir="${buildOutputDir}" dlcHome="${env.DLC}" inputChars="32000" cpInternal="1251" cpStream="ibm866" graphicalMode="true" compileUnderscore="true" >
<fileset dir="${repositoryDir}" >
<include name="**/*.p"/>
<include name="**/*.cls"/>
<include name="**/*.w"/>
</fileset>
<propath>
<pathelement path="${repositoryDir}"/>
<pathelement path="C:\Progress\OpenEdge\gui\netlib\OpenEdge.Net.pl" />
</propath>
<PCTConnection dbName="base1" dbDir="${dbDir}" singleUser="true" />
<PCTConnection dbName="base2" dbDir="${dbDir}" singleUser="true" />
..
<PCTConnection dbName="basen" dbDir="${dbDir}" singleUser="true" />
</PCTCompile>
</target>
</project>
Приложение 4
Сценарий запуска unit-тестов, покрывающих функциональность проекта
<?xml version="1.0" encoding="UTF-8"?>
<project name="Deponet_UnitTests" default="ablunit" basedir="%system. build.checkoutDir%/%SRC_CHECKOUT_FOLDER_NAME%/%SRC_CHECKOUT_FOLDER_NAME%">
<property environment="env" />
<taskdef resource="PCT.properties" classpath="${env.ANT_HOME}\lib\PCT.jar"/>
<typedef resource="types.properties" classpath="${env.ANT_HOME}\lib\PCT.jar"/>
<echo>DLC set to "${env.DLC}"</echo>
<property name="UTDir" value="%system. build.checkoutDir%/%SRC_CHECKOUT_FOLDER_NAME%/%SRC_CHECKOUT_FOLDER_NAME%_test"/>
<echo>UT root directory set to "${UTDir}"</echo>
<property name="dbDir" value="%PROGRESS_ENVIRONMENT_STAGE_FOLDER%" />
<!-- ABLUnit task definition target starts here -->
<target name="taskdef">
<taskdef name="ablunit" classname="com.progress.openedge.ant.ablunit.ABLUnitTask" classpath="${env.DLC}\java\ant-ablunit.jar"/>
</target>
<echo>Set taskdef "ablunit"</echo>
<target name="load" depends="taskdef" description="load data in tables">
<PCTLoadData dlcHome="${env.DLC}" srcDir="${UTDir}\data" errorTolerance="100" cpStream="ibm866" numsep="44" numdec="46" centuryYearOffset="1930" dateFormat="dmy">
<PCTConnection dbName="base1" dbDir="${dbDir}" singleUser="true" />
<PCTConnection dbName="base2" dbDir="${dbDir}" singleUser="true" />
<PCTConnection dbName="base3" dbDir="${dbDir}" singleUser="true" />
</PCTLoadData>
</target>
<echo>Data loaded into databases</echo>
<!-- unit tests start here -->
<target name="ablunit" depends="load" description="runs unit tests">
<mkdir dir="${UTDir}\Results"/>
<mkdir dir="${UTDir}\tempdir"/>
<ABLUnit dlcHome="${env.DLC}" destDir="${UTDir}\Results" tempDir="${UTDir}\tempdir" writeLog="true" cpStream="ibm866">
<PCTConnection dbName="base_" dbDir="${dbDir}" singleUser="true" />
<PCTConnection dbName="pays" dbDir="${dbDir}" singleUser="true" />
<PCTConnection dbName="reestr" dbDir="${dbDir}" singleUser="true" />
<propath>
<pathelement path="${UTDir}\tests"/>
<pathelement path="${UTDir}"/>
<pathelement path="."/>
</propath>
<fileset dir="${UTDir}\tests">
<include name="**\*.cls" />
<include name="**\*.p" />
</fileset>
</ABLUnit>
</target>
</project>


