
Методы извлечения данных
Код на языке программирования Progress ABL(4GL) имеет множество возможностей для извлечения данных. Эффективный запрос может значительно ускорить поиск данных, и наоборот, плохо написанный запрос значительно замедлит этот процесс.
Выбор метода извлечения данных
Во время извлечения записей из базы данных между клиентом и базой пересылается масса сообщений. Чтобы уменьшить их количество необходимо написать код запроса так, чтобы извлекалась только та информация, которая действительно нужна.
Язык ABL предоставляет три основных метода для извлечения информации из базы данных:
- Блоки FOR.
- Операторы FIND.
- QUERY (также называемые GET-запросами).
Сегодня вы узнаете о том, как Progress извлекает данные, как выбирает индекс для использования, и о том, как определить какой метод наиболее подходит для вашей задачи и лучшей производительности.
Что такое ROWID?
Каждая запись (строка) в базе данных имеет уникальный идентификатор строки или ROWID – прямой указатель на местоположение записи в базе данных.
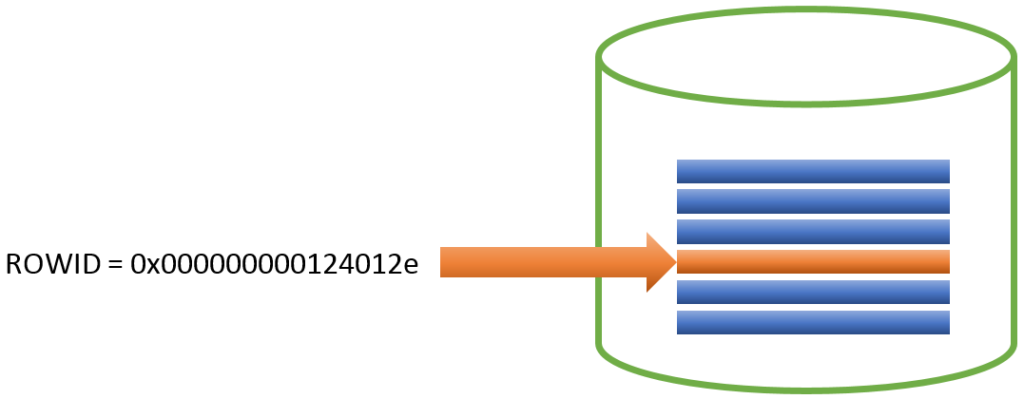
ROWID назначается записи в момент её создания и остаётся с ней на «всю жизнь». Этот идентификатор всегда остаётся неизменным, даже при изменениях значений первичного ключа. Однако после удаления записи ROWID освобождается и может быть переназначен другой вновь созданной записи.
Для извлечения записи из базы данных необходим ROWID. Если ROWID не известен, то для его поиска будет использоваться индекс.
Необходимо стремиться писать код, который извлекает требуемые ROWID с минимальным объёмом трафика.
Если у вас есть возможность выбрать запись по ROWID, то поиск данных будет выполнен в обход индексов и запись будет считана напрямую из базы данных. Это самый быстрый и эффективный метод извлечения данных.
На следующем рисунке показано, как по ROWID определяется точное местоположение записи в базе данных, после чего сервер извлекает её без использования индекса.

Если вы не можете явно использовать ROWID для выбора записи, то используется индекс, который указывает на ROWID.
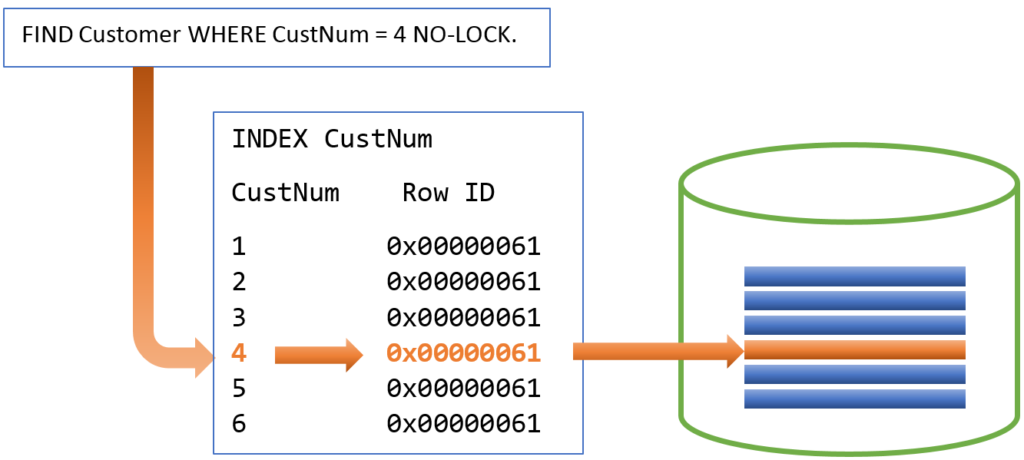
Какой индекс использовать определяется по следующим правилам:
1. Если оператор явно содержит индекс, то использоваться будет этот индекс. Например, в следующем примере будет использоваться индекс Name вместо индекса по умолчанию CustNum:
DO iCust = 1 TO num-entries(pCustList):
FIND NEXT Customer USE-INDEX Name …
…
END.
2. Если индекс заложен в код, то использоваться будет этот индекс. Например, в следующем примере будет использоваться индекс SalesRep вместо индекс по умолчанию CustNum:
FOR EACH Customer WHERE SalesRep = “BBB” …
3. Если не указан какой-либо другой индекс явно или неявно, то будет использоваться индекс по умолчанию. Например, в следующем примере каждая запись будет извлечена с использованием индекса по умолчанию CustNum:
FOR EACH Customer:
Методы извлечения данных
На следующем рисунке демонстрируются три основных метода извлечения одних и тех же данных, в данном случае всех клиентов, чьи имена начинаются на «B».
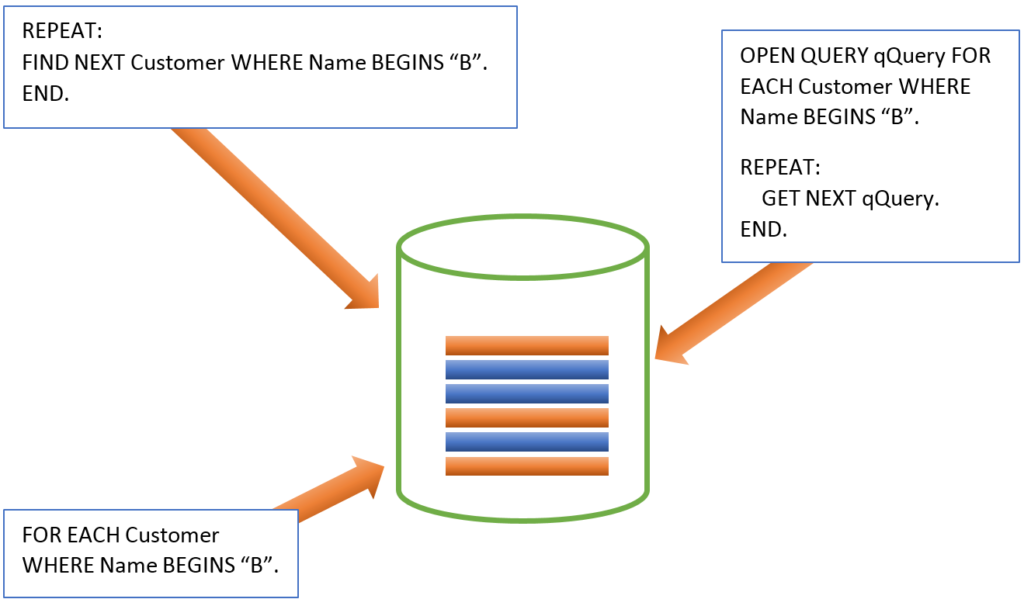
Каждый из этих методов поиска обладает характеристиками, которые определяют для какого типа доступа какой метод использовать. Важно использовать правильный метод чтобы обеспечить наилучшую производительность. Сильные и слабые стороны каждого их них рассмотрены далее.
Использование блоков FOR
Блоки FOR лучше всего подходят для обработки больших объёмов записей. Их следует использовать, когда необходимо:
- перемещение только в одном направление, обработка каждой записи по очереди;
- выполнение одинаковых операций для каждой записи;
- использование условий, например, WHERE, BY или WHILE;
- создание отчётов или списков;
Дополнительно вы можете использовать оператор FOR с ключевыми словами EACH, FIRST или LAST. Например:
FOR FIRST Customer WHERE …
Примечание: FOR FIRST работает быстрее чем FIND FIRST, потому что может использовать несколько индексов.
Преимущества и недостатки использования блоков FOR
Блоки FOR обладают следующими преимуществами:
- Все локировки одинаковые.
- Работает с:
- объединениями (joins);
- сортировками (BY).
- Последовательная обработка записей или объединений, где каждая запись обрабатывается только один раз.
- Использование множественных индексных скобок, которые могут повысить производительность.
Основными недостатками блоков FOR являются:
- Управление не может быть возвращено пользователю до тех пор, пока блок FOR не завершит свою обработку. По этой причине блоки FOR не являются хорошим выбором для программирования логики, управляемой событиями.
- Не допускается навигация, для повторного получения данных блок должен запуститься заново.
Использование FIND
Оператор FIND наилучшим образом подходит для извлечения одной записи с использованием одного индекса и используется когда:
- уже есть RECID/ROWID требуемой записи;
- пользователь ищет конкретную запись;
- достаточно использовать один индекс;
- пользователь просматривает несколько записей, каждая из которых имеет разные критерии выбора;
- не требуются объединения (joins).
Преимущества и недостатки использования FIND
Операторы FIND предназначены для единичного доступа к базе данных, поэтому:
- данные извлекаются быстрее, чем с помощью других методов извлечения данных, которые предназначены для повторяемого доступа;
- данные извлекаются примерно с одинаковой скоростью с использованием FIND FIRST, LAST, PREV и NEXT.
Операторы FIND имеют следующие ограничения:
- используют только один индекс для поиска записей;
- не работают с объединениями (join);
- повторное извлечение записи требует нового поиска.
Использование FIND в цикле
Бывают случаи, когда имеет смысл использовать FIND в цикле вместо оператора FOR EACH:
- FIND в цикле предоставляет возможность контроля в каждой итерации цикла;
- FOR EACH не обеспечивает контроль в отдельных итерациях.

Преимущества каждого метода по производительности определяется наиболее подходящими бизнес-правилами приложения.
Пример использования FIND в цикле
Следующий пример кода демонстрирует возможность программного управления в цикле. Если следующий Клиент не будет найден, то выполнится соответствующее действие.
DO iCity = 1 TO NUM-ENTRIES(pcCityList):
REPEAT: /* start loop */
FIND NEXT customer WHERE City = ENTRY(iCity,pcCityList) NO-ERROR.
IF NOT AVAILABLE Customer THEN
MESSAGE “No customer lives in “ENTRY(iCity,pcCityList)
VIEW-AS ALERT-BOX.
ELSE LEAVE.
END. /* end loop */
...
Ограничения в использовании FIND в цикле
Выполнение FIND или FOR EACH само по себе не приводит к ухудшению производительности. Ключом к хорошей производительности является контекст, в котором они используются.
Следующая таблица сравнения FOR EACH и FIND поможет вам определить, какой метод использовать.
| Условия проектирования | FOR EACH | FIND |
| Использование индексов. | Может использовать несколько индексов. | Использует только один индекс, который может приводить к долгому времени исполнения, если требуется полное сканирование таблицы. |
| Использование выражения BY для сортировки. | Возможно. | Невозможно. |
| Извлечение данных из нескольких таблиц. | Используются объединения (joins) | Требует встроенных блоков REPEAT. |
Использование QUERY
Запросы (query) могут быть как статическими, так и динамическими:
- Статический запрос определяется во время компиляции, поэтому он всегда обращается к одной и той же таблице (таблицам) из той же базы данных.
- Динамические запросы создаются во время исполнения программы и позволяют пользователю указывать таблицы для доступа.
Когда использовать query
Рассмотрите использование query когда:
- хотите передвигаться по записям (scroll) в обоих направлениях, просматривать и выполнять произвольный доступ к записям;
- использовать управляемое событиями программирование;
- необходимо повторно открыть запрос с изменениями (например, поиск с новыми критериями сортировки);
- необходимо обмениваться данными за пределами области действия нормального блока.
Преимущества и недостатки использования QUERY
QUERY имеют много преимуществ, некоторые из них:
- могут использовать несколько индексных скобок;
- работают с объединениями (joins) и сортировками (BY);
- используют список результатов для более быстрого поиска записей;
- имеют объекты с атрибутами и методами, которые позволяют использовать гибкие критерий выборки;
- являются многоразовыми и реконфигурируемыми;
- предоставляют расширенные возможности навигации с опцией REPOSITION;
- поддерживают объединения, BY, PRESELECT, и сортировки;
- не привязаны к блокам 4GL, поэтому на них можно ссылаться из нескольких блоков.
Расширение функциональности требует или приводит к увеличению времени обработки. Некоторые недостатки запросов:
- некоторые опции навигации могут работать медленно, например, GET-LAST в многоиндексном запросе;
- запрос, критерии которого не используют индекс, требуют полного сканирования таблицы для построения списка результатов. Такое сканирование неэффективно и потребляет дополнительные системные ресурсы, такие как чтение дисков и циклы процессора.
Динамические запросы должны использоваться, если вы хотите разрешить пользователю указывать во время исполнения к каким данными должен быть осуществлён доступ.
Преимущество использования динамических запросов в том, что они могут многократно использоваться, поэтому вы можете создать один QUERY для нескольких требований к извлечению данных. Это означает:
- ваше приложение может быть меньше и удобнее в обслуживании;
- ваш r-код может быть значительно меньше;
- меньше кода будет кэшировано, что приведёт к лучшему использованию памяти;
- время развёртывания может быть значительно сокращено.
Недостатком динамических запросов является сложность разработки и реализации, чем статических запросов.
Бенчмаркинг методов извлечения данных
Каждый из трёх методов извлечения данных может использоваться для доступа к одним и тем же данным. Но в некоторых ситуациях вы можете быть не уверены, какой из них будет наиболее эффективен.
Для сравнения скорости извлечения данных разными методами применяется функция ETIME, которая используется для получения времени выполнения операции с последующим сравнением результатов разных тестов.
Функция ETIME измеряет прошедшее время в микросекундах с момента её инициализации до момента завершения операции и получения времени. Результаты функции могут немного отличаться друг от друга при каждом запуске в зависимости от того, что ещё происходит в вашей системе в тоже время. Кроме того, разные компьютеры с разными процессорами то же могут выдавать разные результаты.
Для использования ETIME:
- Обнулите функцию, передав ей положительное логическое значение, например, YES или TRUE.
ETIME(YES).
- Выполните свой код.
- Присвойте значение ETIME переменной, чтобы зафиксировать прошедшее время.
iElapsedTime = ETIME.
Следующая процедура демонстрирует использование функции ETIME для сравнительного тестирования скорости извлечения данных из таблицы Customer разными методами.
/*** Definitions **************************************/ /* Определяем три переменные для хранения значений */ /* прошедшего времени для каждого метода . */ DEFINE VARIABLE iTime1 AS INTEGER NO-UNDO. DEFINE VARIABLE iTime2 AS INTEGER NO-UNDO. DEFINE VARIABLE iTime3 AS INTEGER NO-UNDO. DEFINE QUERY qCustomer FOR Customer. /*** Main Block ***************************************/ /* Извлечение записей с помощью FIND */ /* Инициализируем ETIME для первого метода. */ /* Это также можно записать как ETIME(TRUE). */ /* Инициализация повторяется для каждого */ /* последующего метода */ iTime1 = ETIME(YES). FIND FIRST Customer NO-LOCK. REPEAT: FIND NEXT Customer NO-LOCK. END. /* Сохраняемы прошедшее время в переменной iTime1*/ /* для первого метода */ iTime1 = ETIME. /*Извлечение записей с помощью FOR EACH */ iTime2 = ETIME(YES). FOR EACH Customer NO-LOCK. END. iTime2 = ETIME. /*Извлечение записей с помощью QUERY */ iTime3 = ETIME(YES). OPEN QUERY qCustomer FOR EACH Customer NO-LOCK. GET FIRST qCustomer. DO WHILE NOT QUERY-OFF-END(“qCustomer”): GET NEXT qCustomer. END. iTime3 = ETIME. /*Вывод значений измерения в виде сообщения*/ MESSAGE “Затраченное время на FIND: ” iTime1 SKIP(1) “Затраченное время на FOR EACH: ” iTime2 SKIP(1) “Затраченное время на Query: ” iTime3 VIEW-AS ALERT-BOX INFORMATION.
Метка:Tuning Progress 4GL


